
Due to the expensive costs of collecting labels in multi-label classification datasets, partially annotated multi-label classification has become an emerging field in computer vision. One baseline approach to this task is to assume unobserved labels as negative labels, but this assumption induces label noise as a form of false negative. To understand the negative impact caused by false negative labels, we study how the model's explanation is affected by these labels. We observe that the explanation of the model trained with full labels and partial labels highlights similar regions but with different scaling where the latter tends to have lower attribution scores. Based on these findings, we propose to boost the attribution scores of the model trained with partial labels to make its explanation resemble that of the model trained with full labels. Even with the conceptually simple approach, the multi-label classification performance improves by a large margin in three different datasets on single positive label setting and one dataset on large-scale partial label setting.
Introduction
In a partially annotated multi-label (PAML) classification task, labels are given as a form of partial label, which means only a small amount of categories is annotated per image. This setting reflects the recently released large-scale multi-label datasets, e.g. JFT-300M or InstagramNet-1B, which provide only partial label. Thus, it is becoming increasingly important to develop learning strategies with partial labels. One baseline approach for solving a PAML task is to start by assuming unobserved labels as negative labels (AN). However, this assumption causes label noise in terms of false negatives since the actually positive but unannotated labels are incorrectly assumed to be negative.
we delve into how false negative labels influence a multi-label classification model. We conduct control experiments with two models. One is the model trained with partial labels and AN assumption where false negatives exist, and the other is the model trained with full annotations and thus trained without false negatives. To see the difference in how each model understands the behavior of the model's prediction, we compare the class activation map (CAM) output between the two models.
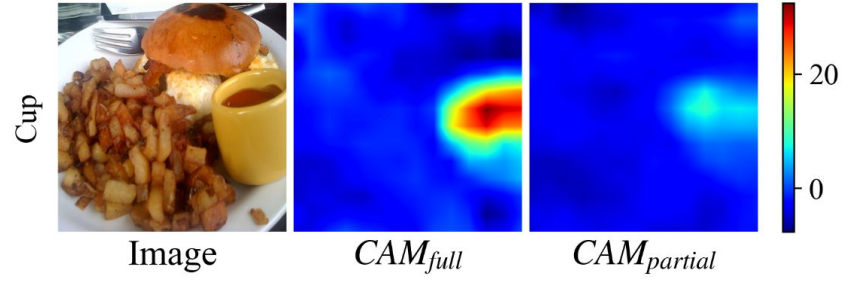
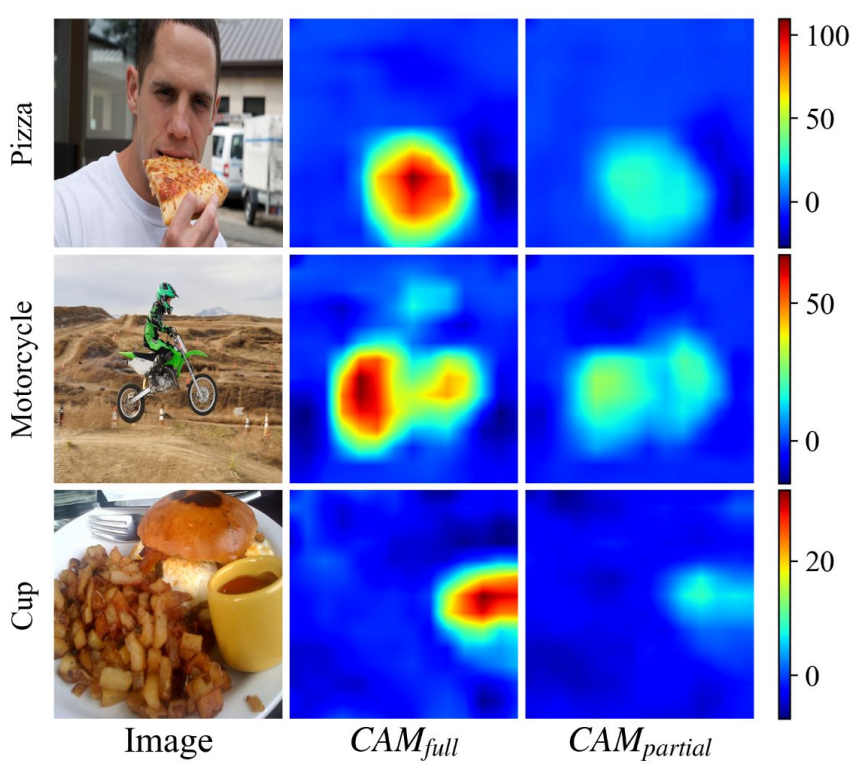
As shown in the figure, we observe that a model trained with false negatives still highlights similar regions to a model trained with full annotation. However, the attribution scores in the highlighted areas are greatly reduced. This observation leads us to think that if we scale up the damaged score of the highlighted region in the model trained with false negatives, the explanation of this model would become similar to that of the model trained with full annotation.
To this end, we introduce a simple piecewise-linear function, named BoostLU, that bridges the gap between the explanation of models trained with false negatives and with full annotation. Concretely, we use the modified CNN model where we can directly get CAM during the forward pass [ACOL] and the logit in the modified CNN model is the average of attribution scores of CAM. The BLU function is applied to the CAM output of the modified CNN to boost the scores of the highlighted regions, thereby compensating for the loss of attribution scores in CAM caused by false negatives. This would lead to an increase in the logit value of positive labels and thus make a better prediction. Furthermore, when BLU is used with the recently proposed methods [LLR] that explicitly detect and modify false negatives, it helps to better detect false negatives and thus leads to better performance.
Preliminaries
Assume Negative in PAML
We aim to train a multi-label classification model with a dataset which consists of pairs of input image and partially annotated label . Each category can have three kinds of labels: 0, 1, and . In other words, where indicates that the category is not annotated and is the number of total categories. Denote the index set of positive labels, negative labels, and unannotated labels as , , and , respectively. We study on the setting where labels are sparsely annotated, i.e., .
A straightforward approach to train the model given partial labels is to treat unannotated labels by assuming negative (AN) and use binary cross entropy as a loss function:
where and is a logit for -th category. However, labels whose true label is positive but unannotated are incorrectly assumed to be negative and become false negatives. Denote the index set of true negative and false negative labels as and , then . We set the approach of training the model with Equation above as the baseline method and investigate the influence of false negatives on the multi-label classification model.
Impact of False Negatives on CAM
It is well known that neural networks are able to memorize wrong labels due to their large model capacities. Likewise, if we train a multi-label classification model with AN loss when given partial labels, the model is damaged by memorizing false negative labels [LLR]. This results in poor performance compared to the model trained with full labels which have no influence of false negatives.
To better understand why the model trained with partial labels has lower performance than that with full labels, we analyze what the behavioral difference is for these two models. Concretely, we use a class activation map (CAM) to explain each model's prediction and compare the explanation results. We train two multi-label classification models on a COCO dataset with the same CNN architecture ResNet50: one model is trained with full labels using binary cross entropy loss, and the other with partial labels using AN loss. We denote the CAM output from each model as \CAMFull and \CAMPartial, respectively.
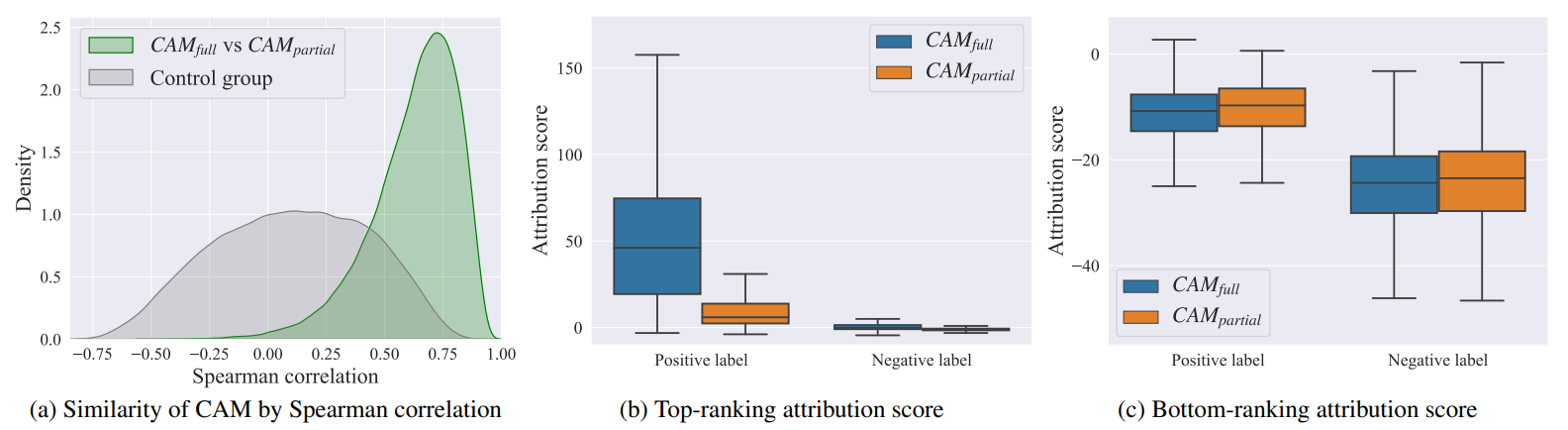
To analyze the explanation of these two models, we first compute the Spearman correlation between \CAMFull and \CAMPartial on positive labels. The distribution of the correlation values on the test set is shown in first figure above. For comparison, we consider a 2D Gaussian image centered at the midpoint and also calculate the Spearman correlation coefficient between this Gaussian image and \CAMFull. We observe that there is mainly a positive correlation between \CAMFull and \CAMPartial while the correlation of the control group is distributed widely but mostly around zero. This implies that the overall structure (i.e. the attribution ranking among pixels) of \CAMPartial is preserved despite the influence of false negative labels, therefore having a high Spearman correlation with \CAMFull.
Since we come to know that the overall structure is similar between \CAMFull and \CAMPartial, we next compare the range of attribution scores between \CAMFull and \CAMPartial. Concretely, we compute the mean of the highest 5% of attribution scores and the mean of the lowest 5% of attribution scores for each CAM and draw the summary of the distribution of these values on the test set where the results are shown in second and third rows in the figure above. Note that we take an average of 5% of scores to take into account potential outliers. We observe that top-ranking attribution scores of \CAMPartial from positive labels drop sharply compared to \CAMFull, while these scores from negative labels remain similar. Also, there is little difference in bottom-ranking attribution scores between \CAMFull and \CAMPartial both on positive and negative labels. This implies that false negatives mainly affect the model's understanding in regions with relatively high attribution scores, especially with respect to positive labels. Consequently, the decrease of attribution scores at certain regions in CAM leads to a decrease in the logit value, making the model predicts lower score for the positive category.
BoostLU
In the previous section, we observe that when a multi-label classification model is trained with AN loss, the way the model understands images is damaged by false negatives. However, we also find that this damage is mainly focused on a drop in the relatively high attribution scores while the overall spatial structure of CAM is preserved. Based on these findings, we conjecture that if the damaged high attribution scores are scaled up in the model trained with partial labels, \CAMPartial would become similar to \CAMFull. To achieve this, we devise a piece-wise linear function, called BoostLU, that boosts the attribution scores that are above 0.
where is a hyperparameter.
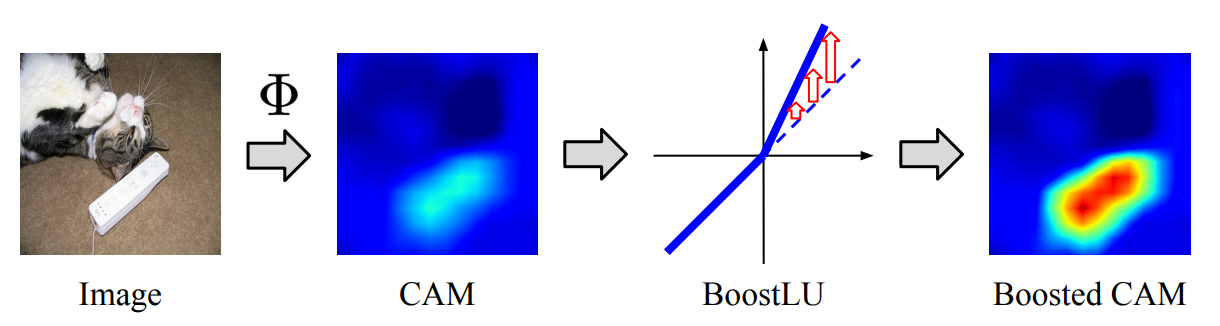
The BoostLU function is applied to the CAM before passing through the GAP layer. By doing so, BoostLU boosts positive attribution scores by times which are the main target to be damaged by false negatives, while maintaining the negative scores unchanged. We further apply BoostLU to the recent methods [LLR] that detect and treat suspicious false negatives during training. When combined with BoostLU, they suppress the side effects caused by false negatives. This helps the model to take full advantage of the boosted gradients from the positive labels during training. Moreover, because these combined methods consider samples with relatively high prediction scores among unobserved labels as false negatives, BoostReLU serves to detect more false negatives by boosting their logit values.
Experiments
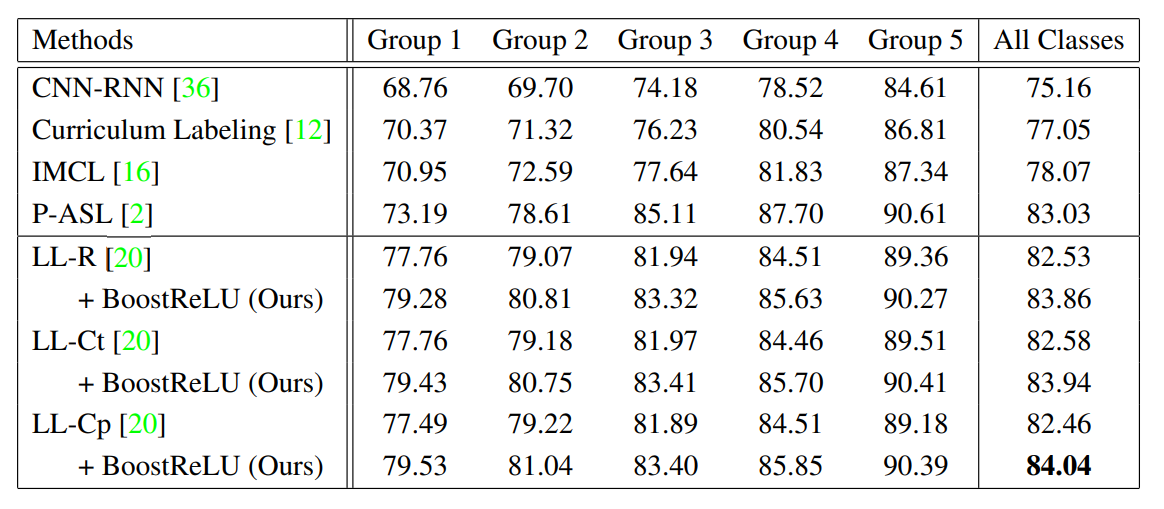
We conduct experiments on 5 datasets, where 4 datasets are artificially curated from the fully-labeled datasets while OpenImages V3 dataset is born to be partially labeled. We here show the results on OpenImages V3, but you can check the results on other datasets in the paper. There are 5,000 classes in the OpenImage V3 dataset. We sort these classes in ascending order by the number of annotations in the training set and divide them into five groups of equal size 1,000. We report the mAP score averaged within each group as well as the entire 5,000 classes.
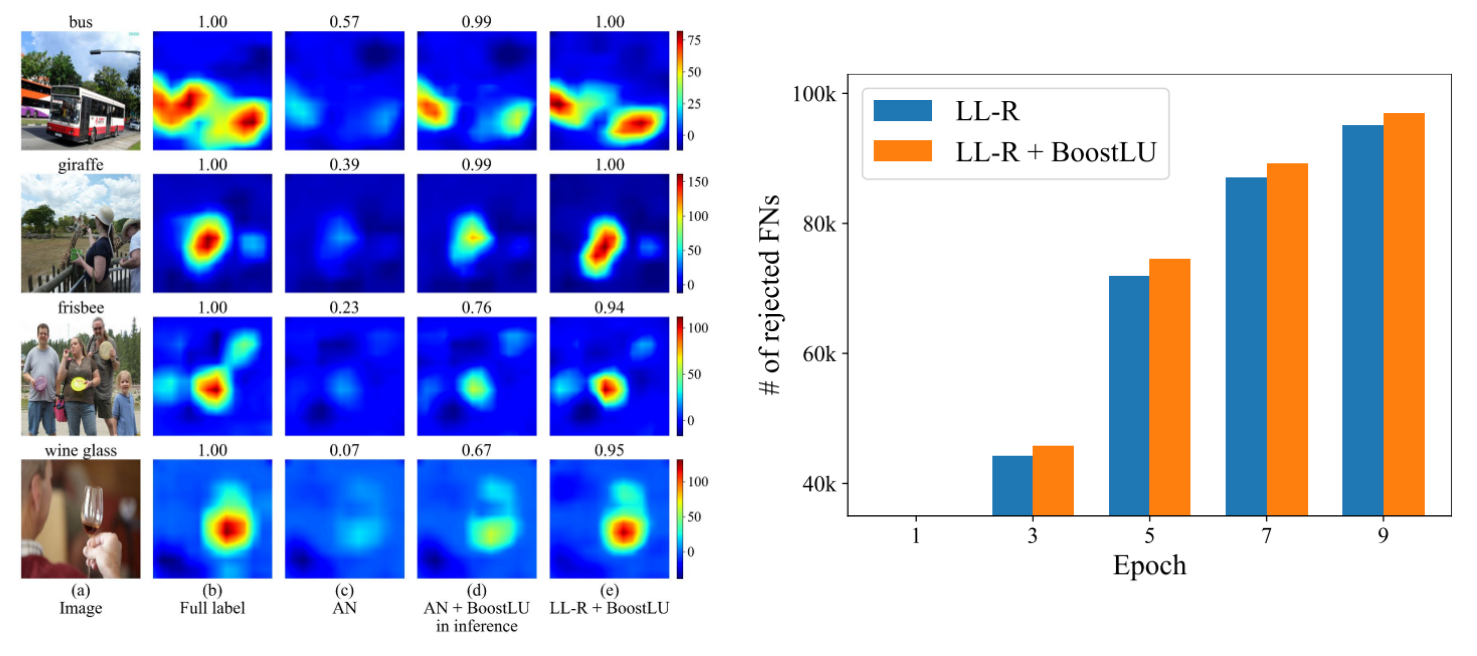
We can also qualitatively check that applying BoostLU recovers the explanation. For LLR + BoostLU, its model explanation is further improved due to the roles of LL-R and BoostReLU during training that further accelerate the improvement of the attribution score of the highlighted region. It can be shown that it is most similar to the explanation of the model trained with full annotation. The right figure below shows the number of false negative labels rejected by each model per epoch. It can be seen that after the warmup phase (first epoch), LL-R + BoostReLU rejects more false negatives than LL-R in every epoch. It is because BoostReLU boosts the logit value of false negative samples and thus boosts the large loss modification methods’ ability to detect false negatives.
Conclusion
We studied the effect of false negative labels on model explanation when assuming unobserved labels as negative in a partially annotated multi-label classification situation. We found that the overall spatial shape of the explanation tends to be preserved but the scale of attribution scores is significantly affected. Based on these findings, we proposed a conceptually simple piece-wise linear function BoostLU that compensates for the damaged attribution scores. Through several experiments, we confirmed that BoostLU successfully contributed to bridging the explanation of the model closer to the explanation of the model trained with full labels. Furthermore, when combined with large loss modification methods, it achieved state-of-the-art performance on several multi-label datasets.
References
[ACOL] Zhang et al., Adversarial complementary learning for weakly supervised object localization, CVPR, 2018.
[LLR] Kim et al., Large Loss Matters in Weakly Supervised Multi-Label Classification, CVPR, 2022.