
Given an image and a target modification (e.g an image of the Eiffel tower and the text "without people and at night-time"), Compositional Image Retrieval (CIR) aims to retrieve the relevant target image in a database. While supervised approaches rely on annotating triplets that is costly (i.e. query image, textual modification, and target image), recent research sidesteps this need by using large-scale vision-language models (VLMs), performing Zero-Shot CIR (ZS-CIR). However, state-of-the-art approaches in ZS-CIR still require training task-specific, customized models over large amounts of image-text pairs. In this work, we propose to tackle CIR in a training-free manner via our Compositional Image Retrieval through Vision-by-Language (CIReVL), a simple, yet human-understandable and scalable pipeline that effectively recombines large-scale VLMs with large language models (LLMs). By captioning the reference image using a pre-trained generative VLM and asking a LLM to recompose the caption based on the textual target modification for subsequent retrieval via e.g. CLIP, we achieve modular language reasoning. In four ZS-CIR benchmarks, we find competitive, in-part state-of-the-art performance - improving over supervised methods. Moreover, the modularity of CIReVL offers simple scalability without re-training, allowing us to both investigate scaling laws and bottlenecks for ZS-CIR while easily scaling up to in parts more than double of previously reported results. Finally, we show that CIReVL makes CIR human-understandable by composing image and text in a modular fashion in the language domain, thereby making it intervenable, allowing to post-hoc re-align failure cases._
Introduction
Compositional Image Retrieval (CIR) is the task of understanding both the input image and the textual query and retrieving the relevant target image. While there have been numerous works that train specific models for this task, we are interested in approaching the problem from a zero-shot setting (ZS-CIR) i.e not assuming that we have paired triplets of (source,modifier,targets). Furthermore, we show that it is indeed possible to achieve this task without training any model specifically for this task. We simply rely on existing vision and language models to be able to solve this task.
Approach
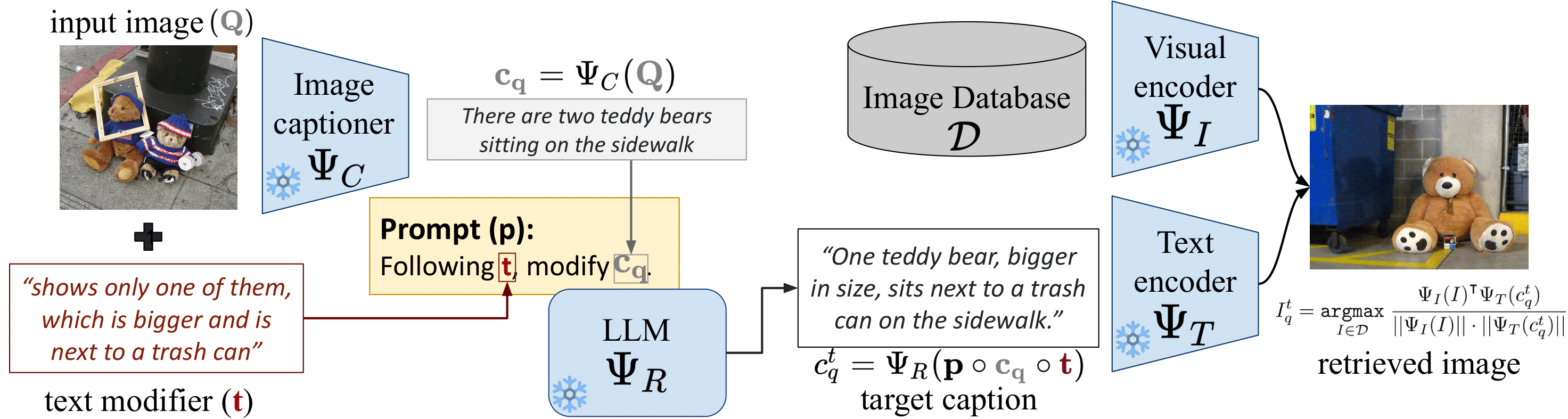
The key insight of our work is built on existing ZS-CIR approaches which map an image to a pseudo-token and concantenate this token with the textual modifier. This lets us ask the question if we can simply perform the reasoning fully in the language domain, thereby keeping the process training-free and human understandable?
To do this, we first caption the source image using an off-the-shelf captioning model such as BLIP-2 or CoCa. Then we provide this caption and the textual modifier to an LLM along with a few in-context examples. The LLM then provides a plausible caption for the target image. We then directly search for this image using a text-image retrieval such as CLIP.
Results
CIReVL achieves state-of-the-art results on the CIRCO, CIRR, Fashion-IQ and GeneCIS benchmarks. You can see the numbers in the paper, but here we show a few examples.
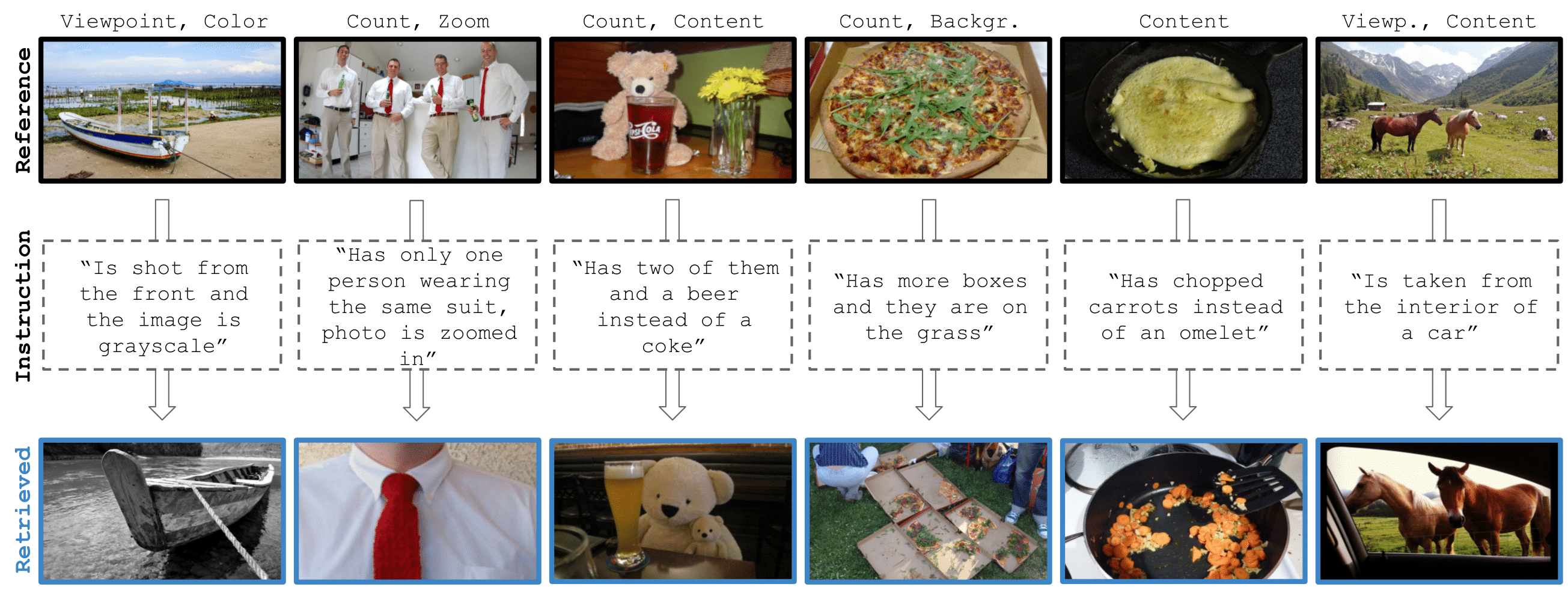
A major benefit of our method is that in the cases where we are not successful, we can pinpoint the error to the various components: captioning, LLM modifier, text-image retrieval, or just dataset ambiguity. Additionally, the user can also fix the error which can then improve the performance.

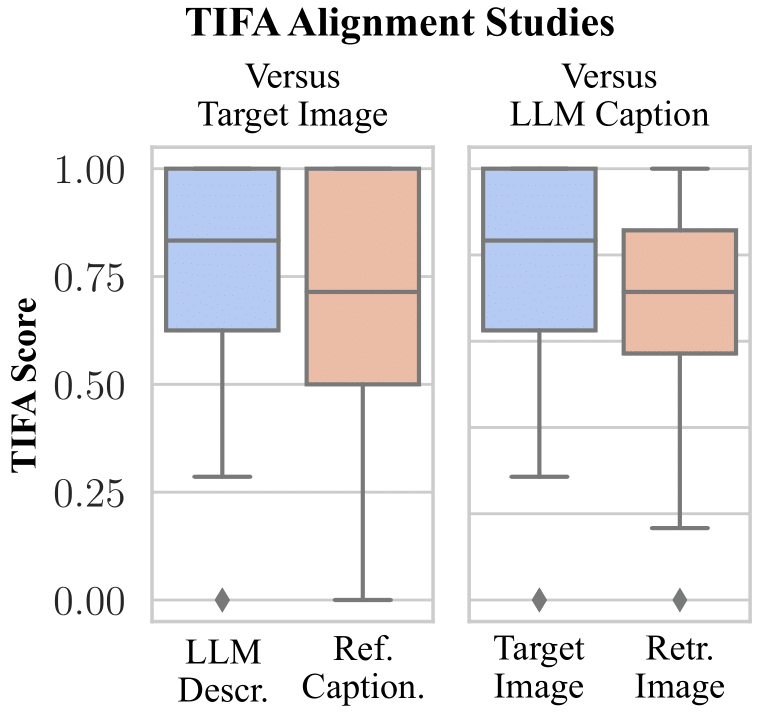
We also investigate the bottlenecks of our pipeline. We see that the text-image model used for retrieval is an issue by using a better image-text alignment model (eg. TIFA) and seeing that the ground truth image is more aligned with the querying caption than the image retrieved by the CLIP model.
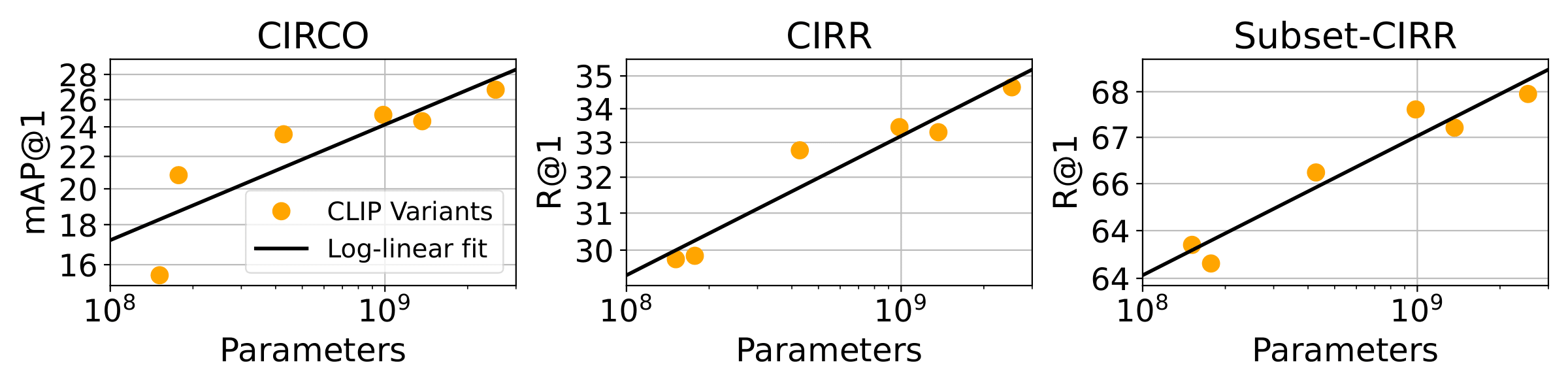
This naturally raises the question, can we simply scale up the size of the CLIP model leaving everything else unchanged and see improved performance? Indeed, we see that as we scale the retrieval model from ~50M parameters to ~2B parameters, we see a log-linear increase in performance.
We hope you found this interesting, for more results and analysis, please refer to the paper and our code.