
Training deep networks requires various design decisions regarding for instance their architecture, data augmentation, or optimization. In this work, we find these training variations to result in networks learning unique feature sets from the data. Using public model libraries comprising thousands of models trained on canonical datasets like ImageNet, we observe that for arbitrary pairings of pretrained models, one model extracts significant data context unavailable in the other -- independent of overall performance. Given any arbitrary pairing of pretrained models and no external rankings (such as separate test sets, e.g. due to data privacy), we investigate if it is possible to transfer such "complementary" knowledge from one model to another without performance degradation -- a task made particularly difficult as additional knowledge can be contained in stronger, equiperformant or weaker models. Yet facilitating robust transfer in scenarios agnostic to pretrained model pairings would unlock auxiliary gains and knowledge fusion from any model repository without restrictions on model and problem specifics - including from weaker, lower-performance models. This work therefore provides an initial, in-depth exploration on the viability of such general-purpose knowledge transfer. Across large-scale experiments, we first reveal the shortcomings of standard knowledge distillation techniques, and then propose a much more general extension through data partitioning for successful transfer between nearly all pretrained models, which we show can also be done unsupervised. Finally, we assess both the scalability and impact of fundamental model properties on successful model-agnostic knowledge transfer.
Start Here
Modern deep networks are (pre)trained on canonical datasets such as ImageNet under various design decisions - covering for instance their architecture, data augmentation, optimization method and even smaller, but still important factors such as the data ordering. This means that training data is received and integrated in differing fashions. But does this mean that each model acquires a somewhat "unique" understanding of the data? And if so, what can we do with that?
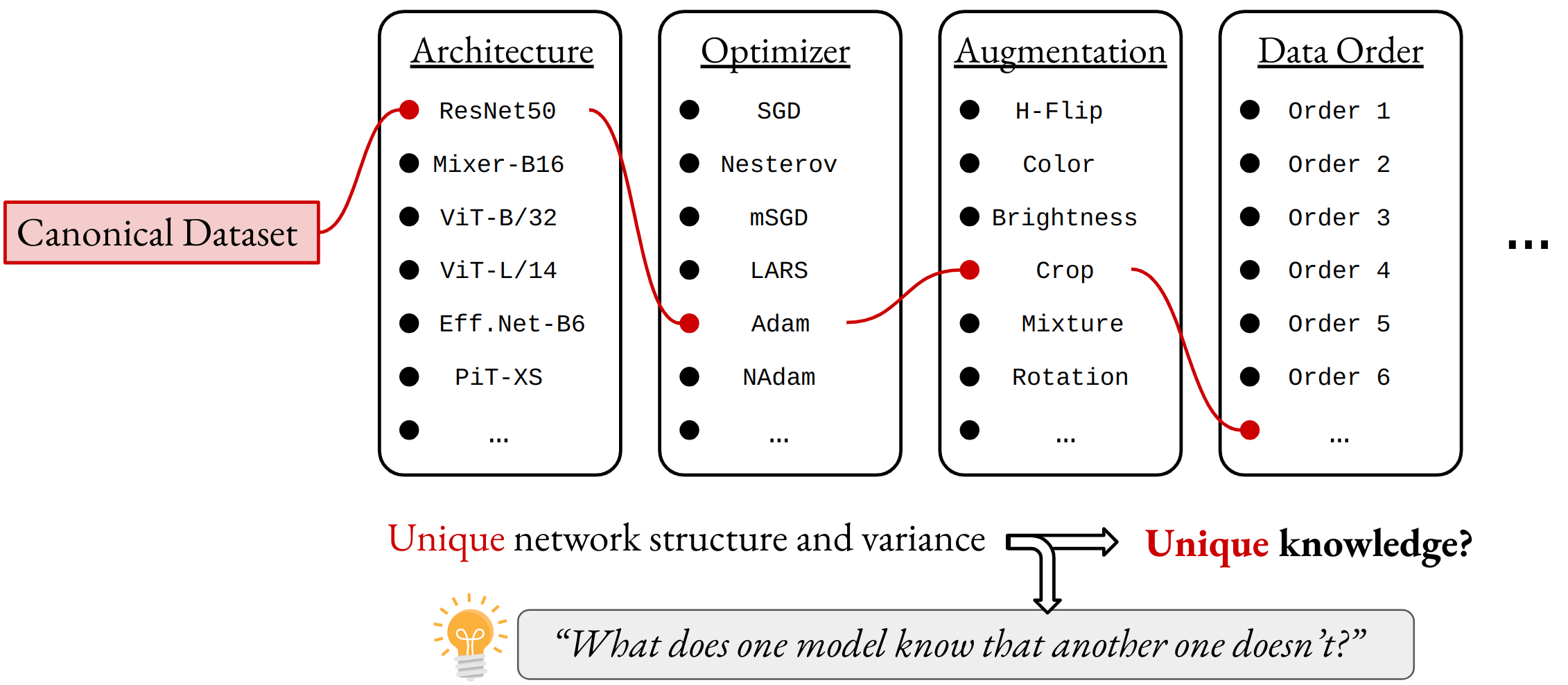
In our work, we try to provide insights and answers into both questions. Using large public model libraries, which comprise thousands of models trained on canonical datasets such as ImageNet, we first observe that for any pair of (sufficiently) trained model, complementary knowledge exists.
Finding complementary knowledge:
Definition (Complementary Knowledge). On a high level, it refers to context about the data domain that one model (denotes as the "teacher") is aware of which the other one (the "student") is not. For example, in the case of classification-based models with some test set evaluating the generalization capabilities, this simply refers to the samples that are correctly classified by one model, and incorrectly classified by another.
Indeed, plotting this complementary knowledge as a function of the test accuracy differences gives us this figure:
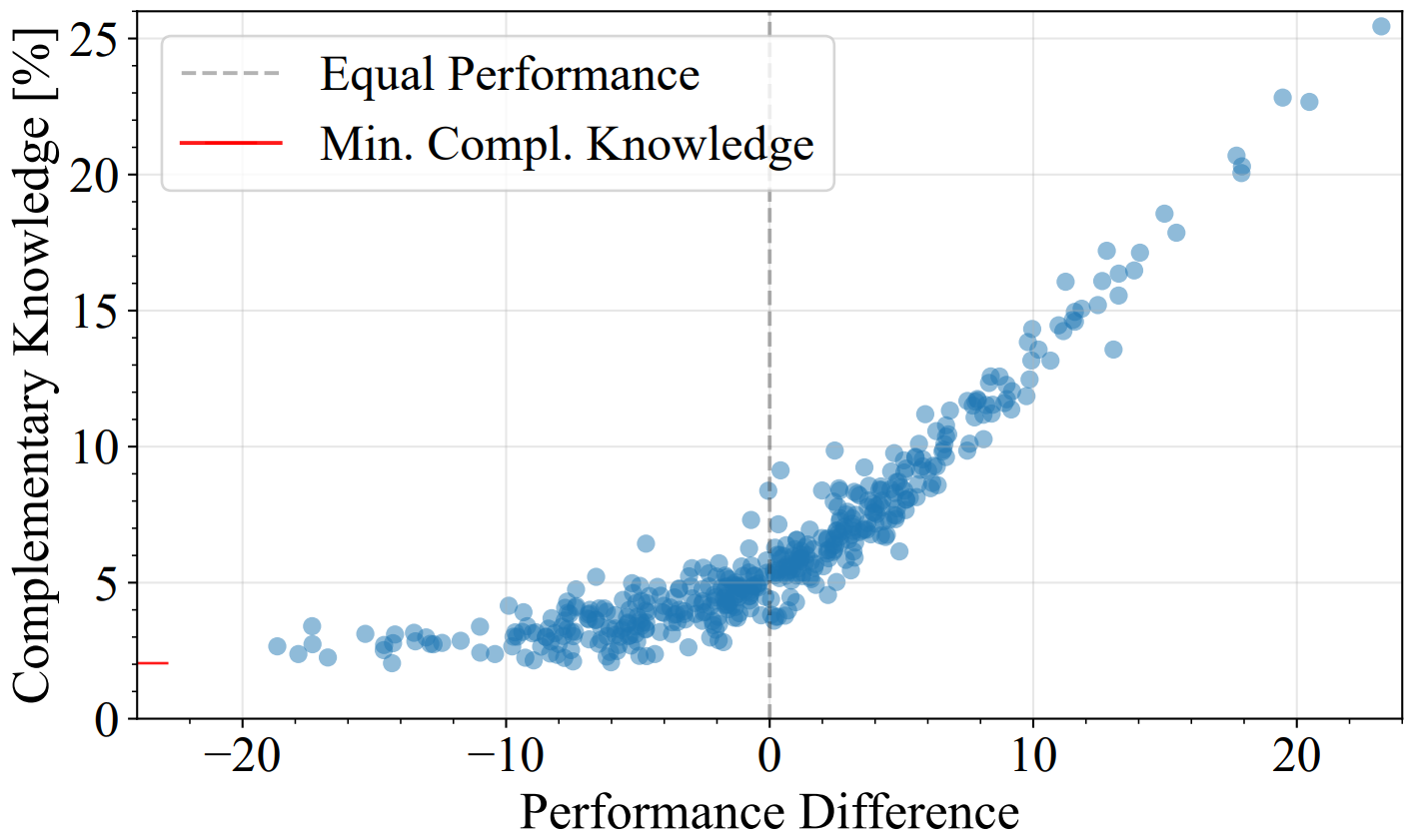
For any pairing we tested (and by extension the majority of model pairings available in public repositories such as timm or huggingface), the complementary knowledge is significant ( where e.g. a randomized ResNet50 teacher may give ).
So what does this complementary knowledge look like?
Definition (Positive and Negative Flips). We denote a sample as being "positively" flipped by a teacher with respect to some student, if it was originally classified incorrectly by the student, but is correctly assigned to its ground truth class by the teacher. Negative flips work the opposite way.
Looking at the distribution of positive flips from exemplary "weak", "equiperformant" and "strong" teachers (which can be seen as the complementary knowledge from the teacher w.r.t. the student), we find that these tend to focused around certain classes:
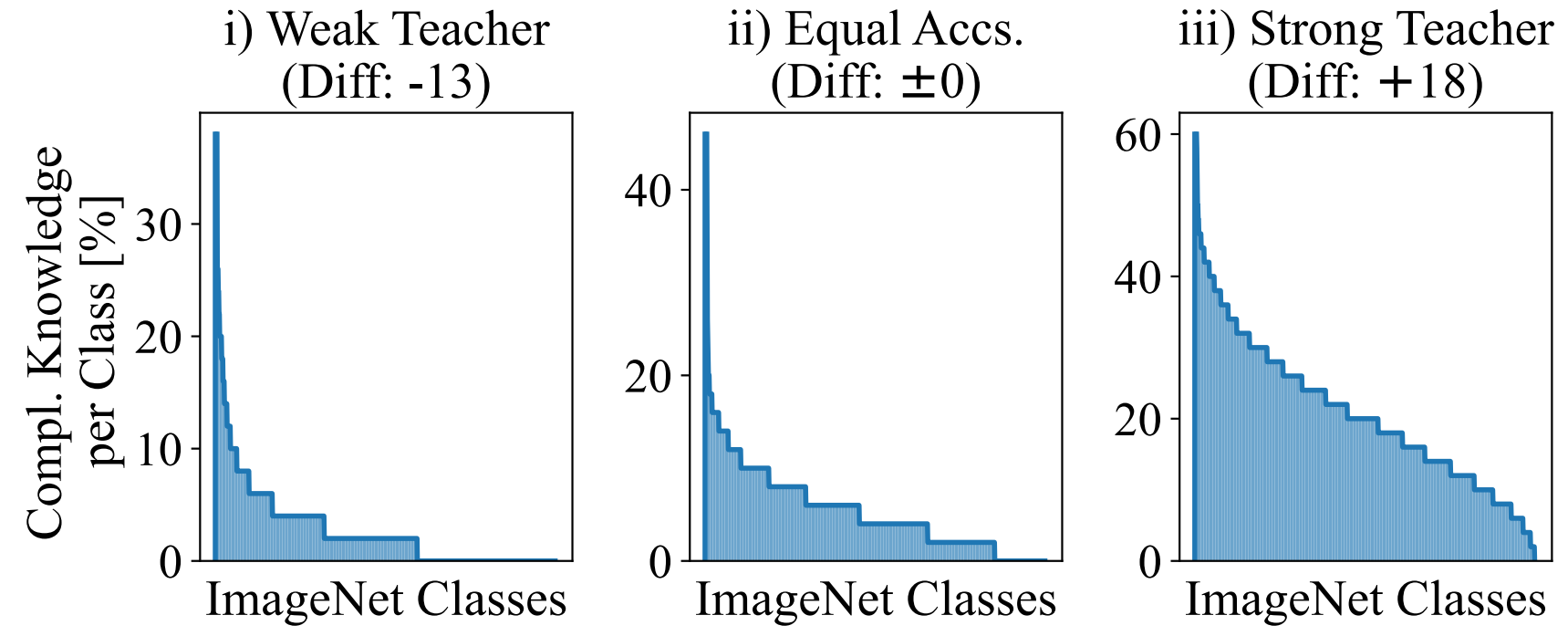
This means that there are consistently some classes where a teacher can disproportionally support the student on. And it turns out that more likely than not, these "important" classes are semantically related (measuring similarity via LLM embeddings for respective classnames):
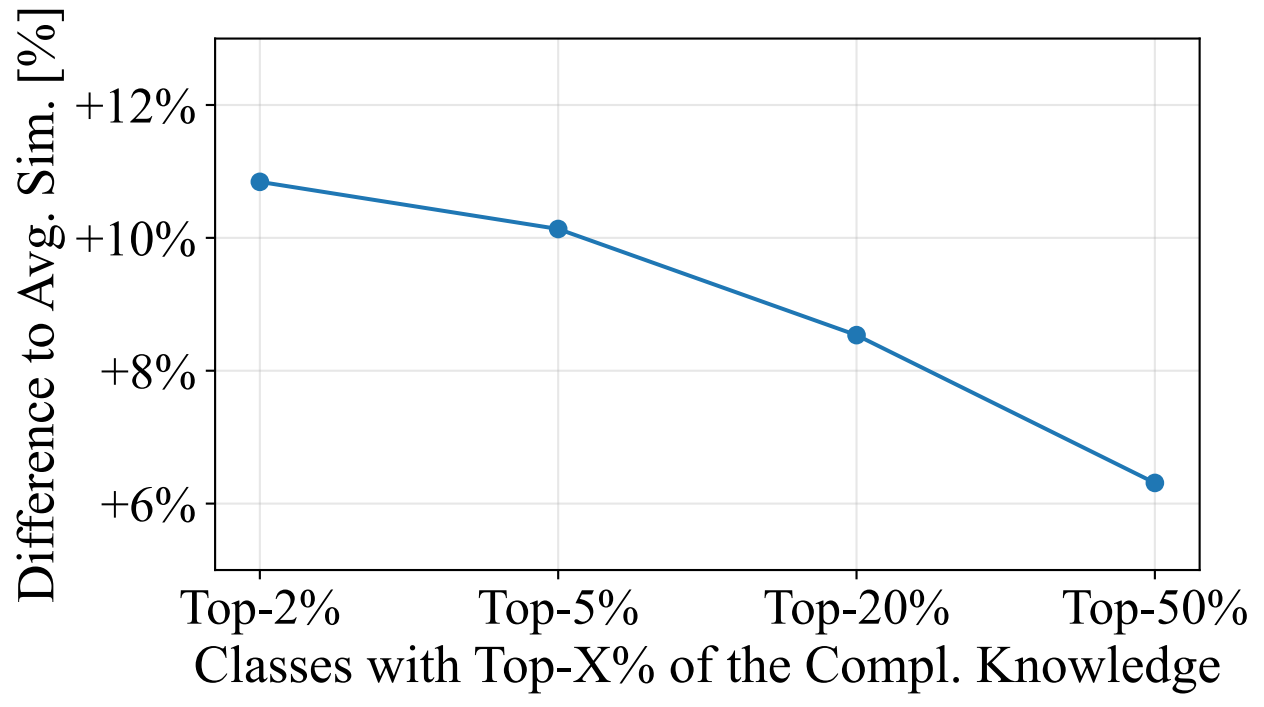
We consequently call these class groups a teachers areas of expertise.
Even when trained on the same dataset, different models have complementary information about the data. Now what?
As the large majority of model pairings have complementary information, the immediate next question for us was: What can we do with it? And in more practical terms:
Research Question: Can I actually transfer this complementary knowledge from one model to another one - without making any restrictions on teacher and student architecture, training context and most importantly, relative performance?
The latter is particularly interesting. As our experiments show, even when the teacher is weaker by a significant percentage, the samples it classifies correctly aren't just a subset of the stronger student model, but likely contextual subset of the data with semantic relevance to the student (we find that this holds both for models that share the same architectural family (CNN, Transformer, MLP), and models within the same family).
So how can I transfer this information for a weaker teacher?
Well, even if the teacher is equiperformant or stronger (by some test evaluation measure), and has more complementary context to offer, simple transfer my not be as straightforward and actually help improve the model: Since the student is pretrained as well, there is a good chance that we override its knowledge when e.g. leveraging distillation approaches.
As such, finding a way to develop a general knowledge transfer mechanism is a very interesting research question.
Why should I care about general knowledge transfer?
Before diving into what we tried to tackle this problem setting, it makes sense to understand why general knowledge transfer is of practical interest.
Some interesting pointers in that regard:
- One could train multiple models independently in a federated fashion, and try to transfer the additionally gained context from one into another model. Even if one chooses an untrained base model to transfer knowledge too, as soon as multiple models are involved and transfered from at different points in time, it becomes a general transfer problem.
- It also opens up public repositories of pretrained models as an orthogonal measure to raise performance of a freely chosen (for reason such as speed, fairness, interpretability, size, ...) base model pretrained on the same canonical dataset.
- As (in parts much) weaker models can provide useful context, one can also train multiple smaller and more compute efficient models and try to integrate this information into the chosen base model. In a similar fashion, when training a large model on a big dataset, additional gains could be included when integrating smaller models to transfer knowledge from.
- As we show, this can be done even without label information / expert knowledge about the canonical dataset!
So how is this done?
Naturally, the easiest way to do this is to leverage well known knowledge distillation methods, e.g. computing the KL-Divergence between output class distributions (we also tested other approaches, e.g. contrastive distillation, but which we found doesn't work as well across different architectures). Unfortunately, it turns that this doesn't work as well out of the box - while it gives good gains so long as the teacher is notably stronger, it simply overwrites the student knowledge (right plot below). We show this by measuring the success rate of transfer (i.e. where the student performance is higher than initially):
![]()
Results for standard distillation success rates are in the left plot, left-most bar, given only . As such, if the teacher is weaker or equiperformant, performance drops. Same holds when we add a standard, label-dependent classification objective into the distillation process to try and retain same student knowledge (bar second-from-the-left).
As such, we utilize approaches from continual learning and model merging. There are different ways to restrict how much a model can change after gradient updates - but we found simple interpolation to work best (i.e. consistently interpolating back to previous model weights as transfer progresses). Going by the success rate, we find a clear increase (XE-KL-Dist + MCL Transfer, ).
However, when looking at what happens for both weaker and stronger teachers, the high success rate is put into a more sobering perspective: While the strong restriction on adaptation ensures benefits for weaker teachers, the benefit from stronger teachers suffers notably.
So how can we get the best from both worlds? One methods restricts the change too much on a weight level, while the other has no restrictions in place. As such, we want to find something in-between. And indeed, we found a convincing first solution by looking not at weight-level restrictions on the adaptation, but rather the data-level:
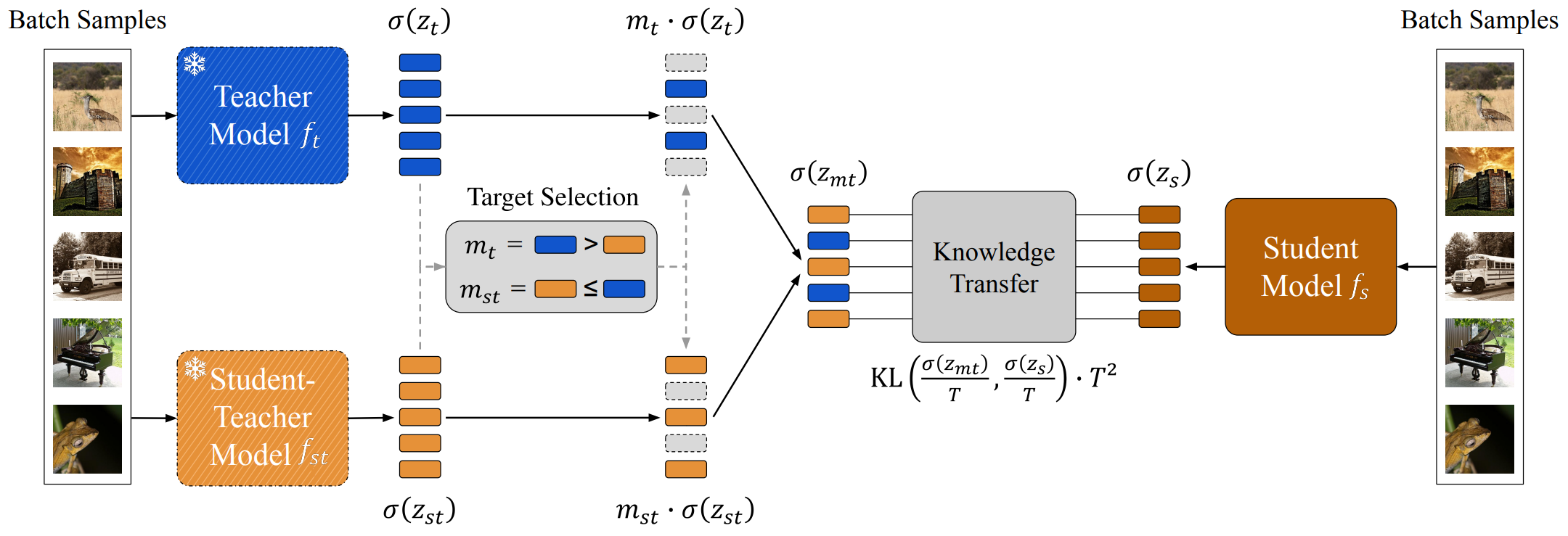
In particular, we simply select data points where we want to distill knowledge from the teacher, and those where we want to avoid this, and instead distill from our original, untouched student. By default, one can leverage class labels to make this selection: Whenever a sample falls into the complementary regime of the teacher, we distill from it, and otherwise we don't. Compared to the other approaches (see previous plot, rightmost bar), this not only raises the overall success rate, but also gives both complementary knowledge transfer for weaker teacher, and strong transfer from strong teacher models.
Even more, with this setup, it is indeed the complementary knowledge that is transferred (first):
![]()
Finally, we round this up by showing that one can get similar transfer success without any labels, but instead just going by model confidence - distilling from the teacher on a sample when it has higher confidence (maximum logit value), and from the pretrained student otherwise. Of course, there is no free lunch, and such an approach introduces selection biases and higher variance in the final results. However, practically, we found that this unsupervised approach works incredibly well, most of the times matching or even outperforming the supervised counterpart!
What's next?
There are a lot of things that we didn't manage to cover in this paper, and that are all equally interesting to investigate further:
- Can one find similar results beyond classification models on ImageNet - e.g. CLIP-style models? And how would a general knowledge transfer mechanism best look here?
- What are the limit cases? I.e. the existence of complementary knowledge does not hold forever. At some point, the teacher is either to weak or the student too strong. And how are these limits impacted by different architectural coices?
- In this paper, we tested ImageNet (and some other benchmark datasets as well). But looking at it on a mucher larger scale could introduce some new insights!
- Method improvements: We find that complementary knowledge can be somewhat generally transferred - but currently, the overall amount that is transferred can still be notably improved.
- Finally, it is very interesting to understand what is possibly transferred beyond complementary knowledge - such biases, robustness properties, ...
If you find these questions interesting (and don't want to work on them on your own), feel free to also reach out to us, we are always interested to chat about this!
Want to know more?
We have a lot more results, and much more detailed information in the actual paper - such as actual numbers, current limits, transfer from multiple teachers, .... So please take a look at it if you want to know more about this topic!