
Deep Metric Learning (DML) proposes to learn metric spaces which encode semantic similarities as embedding space distances. These spaces should be transferable to classes beyond those seen during training. Commonly, DML methods task networks to solve contrastive ranking tasks defined over binary class assignments. However, such approaches ignore higher-level semantic relations between the actual classes. This causes learned embedding spaces to encode incomplete semantic context and misrepresent the semantic relation between classes, impacting the generalizability of the learned metric space. To tackle this issue, we propose a language guidance objective for visual similarity learning. Leveraging language embeddings of expert- and pseudo-classnames, we contextualize and realign visual representation spaces corresponding to meaningful language semantics for better semantic consistency. Extensive experiments and ablations provide a strong motivation for our proposed approach and show language guidance offering significant, model-agnostic improvements for DML, achieving competitive and state-of-the-art results on all benchmarks.
Introduction
Deep Metric Learning, and by extension visual similarity learning has proven important for applications such as image retrieval, face verification, clustering or contrastive supervised and unsupervised representation learning. In most visual similarity tasks, transfer beyond the training distribution and classes is crucial, which requires learned representation spaces to encode meaningful semantic context that generalizes beyond relations seen during training.
However, the majority of DML methods introduce training paradigms based only around class labels provided in given datasets, which does not account for high-level semantic connections between different classes (e.g. sports cars vs. pickup trucks) can’t be accounted for. To address this problem, we propose to leverage large-scale pretrained natural language models to provide generic and task-independent contextualization for class labels and encourage DML models to learn semantically more consistent visual representation spaces.
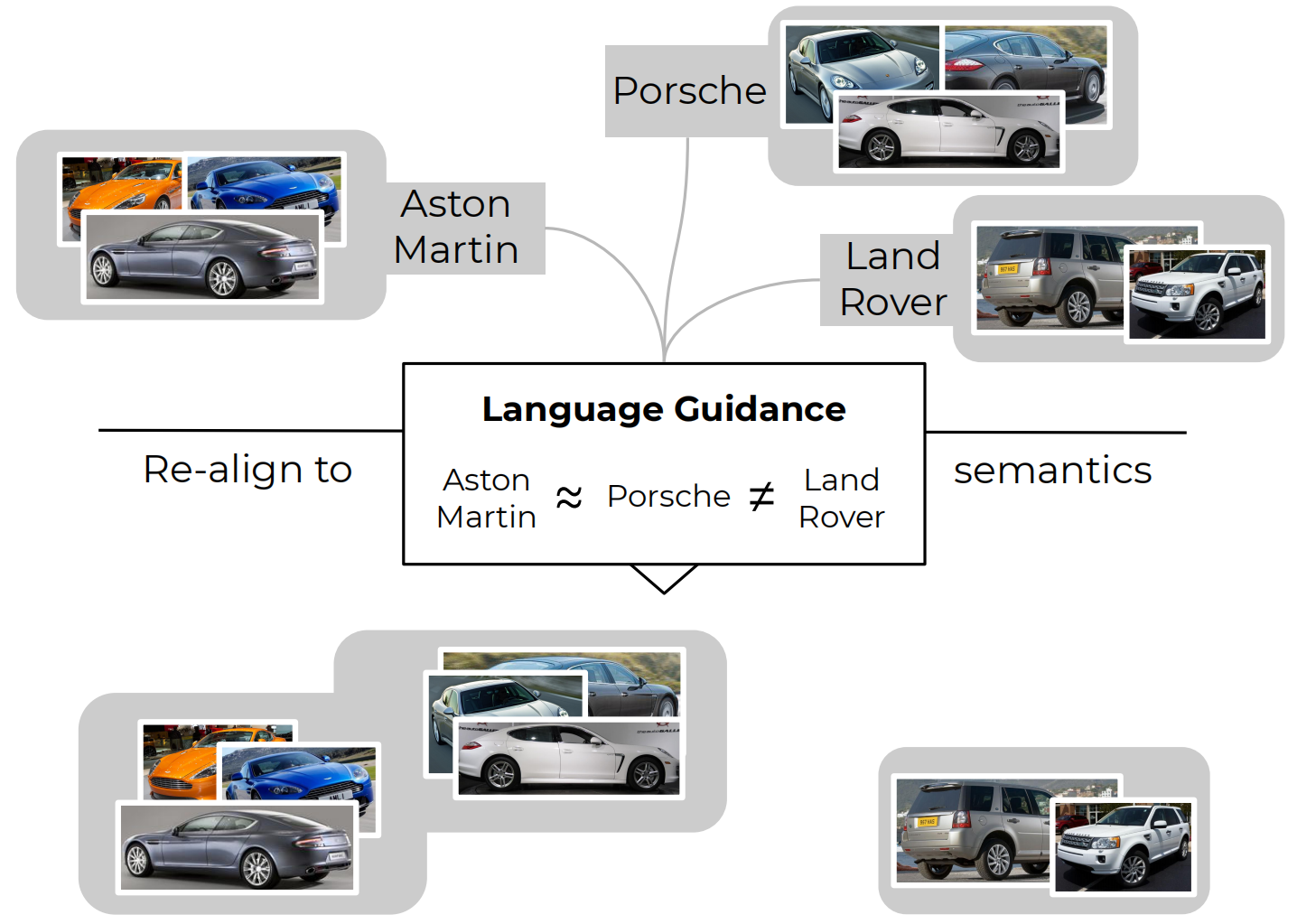
Using language-based pretraining for contextualization of visual similarities is long overdue - for vision-based DML, image pretraining (on ImageNet) has already become standard, providing a strong and readily available starting point and ensuring ranking tasks underlying most DML methods to be much better defined initially. Thus, there is little reason to bottleneck DML to only leverage visual pretraining while disregarding the potential benefits of language context.
Contributions
To address this issue, we thus
- describe how pretrained language models can be used to re-align vision representation spaces when expert labels are available,
- and showcase approaches for re-alignment when only ImageNet pretraining is given via pseudolabels,
Utilising language guidance, we are able to
- easily achieve new state-of-the-art performance with little hyperparameter tuning,
- show through multiple ablations the validity of our approach and the impact on language guidance on improved retrieval capabilities based on actual semantics,
- and intregrate language guidance with little impact on the overall training times.
Integrating Language Guidance
The standard DML pipeline utilizes an ImageNet-pretrained feature extraction network and a small projector on top to offer a deep and non-linear map from Imagespace to (pseudo-)metric representation space , on top of which standard DML approaches can be utilized as surrogate objectives to structure the metric space. These methods optimize for a simple non-parametric distance metric such as the euclidean distance d = , such that simple distances between representations , has strong connections to the underlying semantic similarities of .
Most standard, supervised DML objectives rely on the available class-level supervision to define for example ranking objectives. But as this is insufficient to capture higher-level semantic relations between classes, we now propose a first simple approach to leverage expert label information to update the visual similarity space.
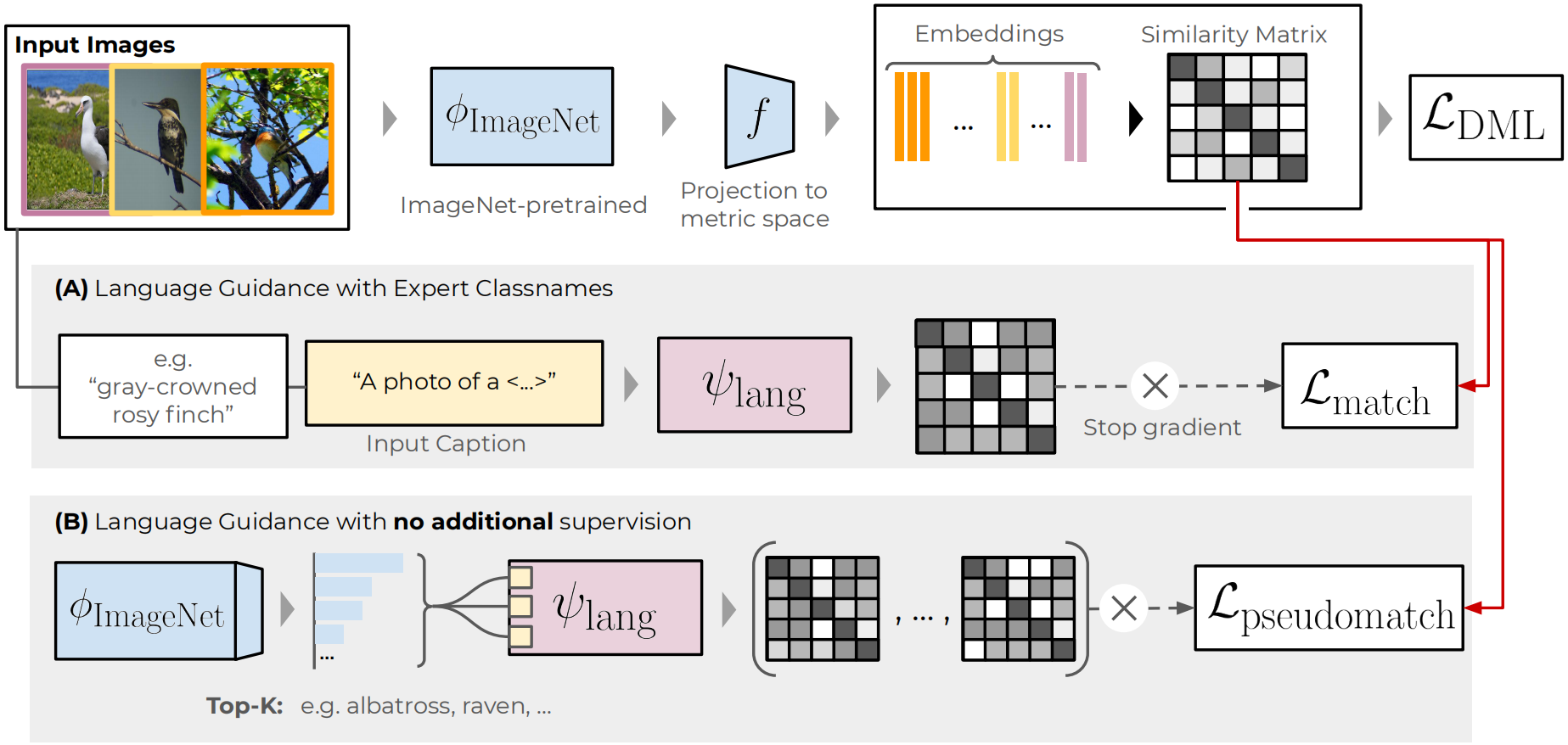
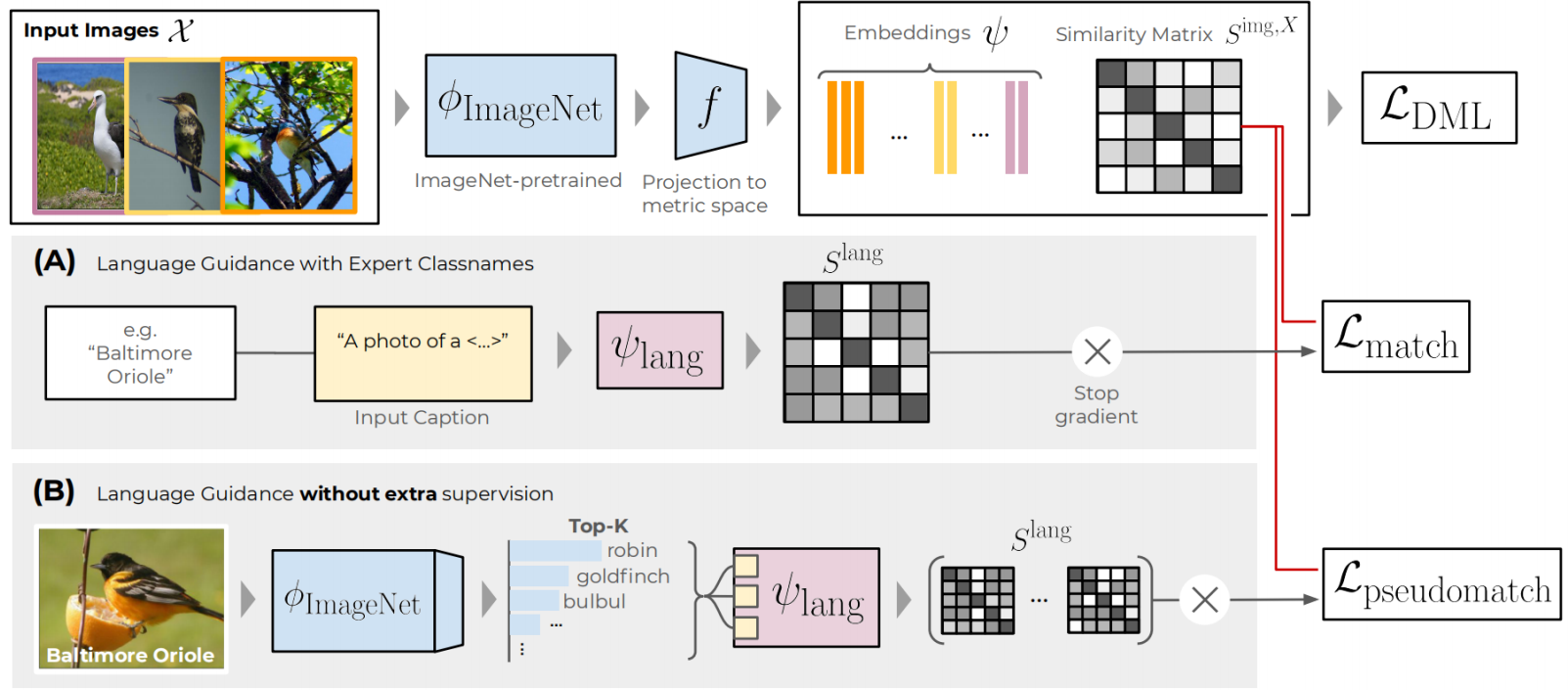
With Expert Labels
Given a minibatch of images, we first extract vision representations, , and compute the similarity matrix .
In a second step, we leverage large-scale language pretrained encoders , such as BERT, RoBERTa or CLIP-L, and for each batch element extract the expert classname . The classnames are then embedded into a caption with some primer giving e.g. .
These captions are then feed into to compute the respective language embeddings and similarity matrix .
In doing so, represents the semantic relations between each class, which we want to utilize to re-align the finegrained visual representation space computed using and .
This is done by optimzing the language distillation loss
which computes the KL-Divergence between all similarities for a given anchor sample , with softmax function and shift to address the "exactness" of the distribution match. Finally, as does not resolve similarities for samples within a class unlike (for and we have and thus , but, since the classes are the same, ). To ensure that we do not lose intraclass resolution during distillation, we thus adapt :
The total objective is thus given as
with ELG abbreviating Expert Language Guidance. A visual summary of this approached is given in above figure.
With Pseudo-Labels
However, expert labels aren't easy to come buy and often not available. For practical use, we thus extend our language guidance to one that solely relies on the ubiquitous ImageNet-pretraining of DML pipelines.
For a given training dataset , we thus take the ImageNet-pretrained backbone including the classification head and for each image compute the top-k ImageNet classes .
This gives a sample-level semantic supervision, which we can also aggregate for each class to give the top-k respective pseudoclasses. Then, in a similar fashion to the expert label setup, we can for each pseudoclass label compute respective pseudo-label semantic similarity matrices and aggregate these into a pseudo-label distillation objective:
Experiments Results
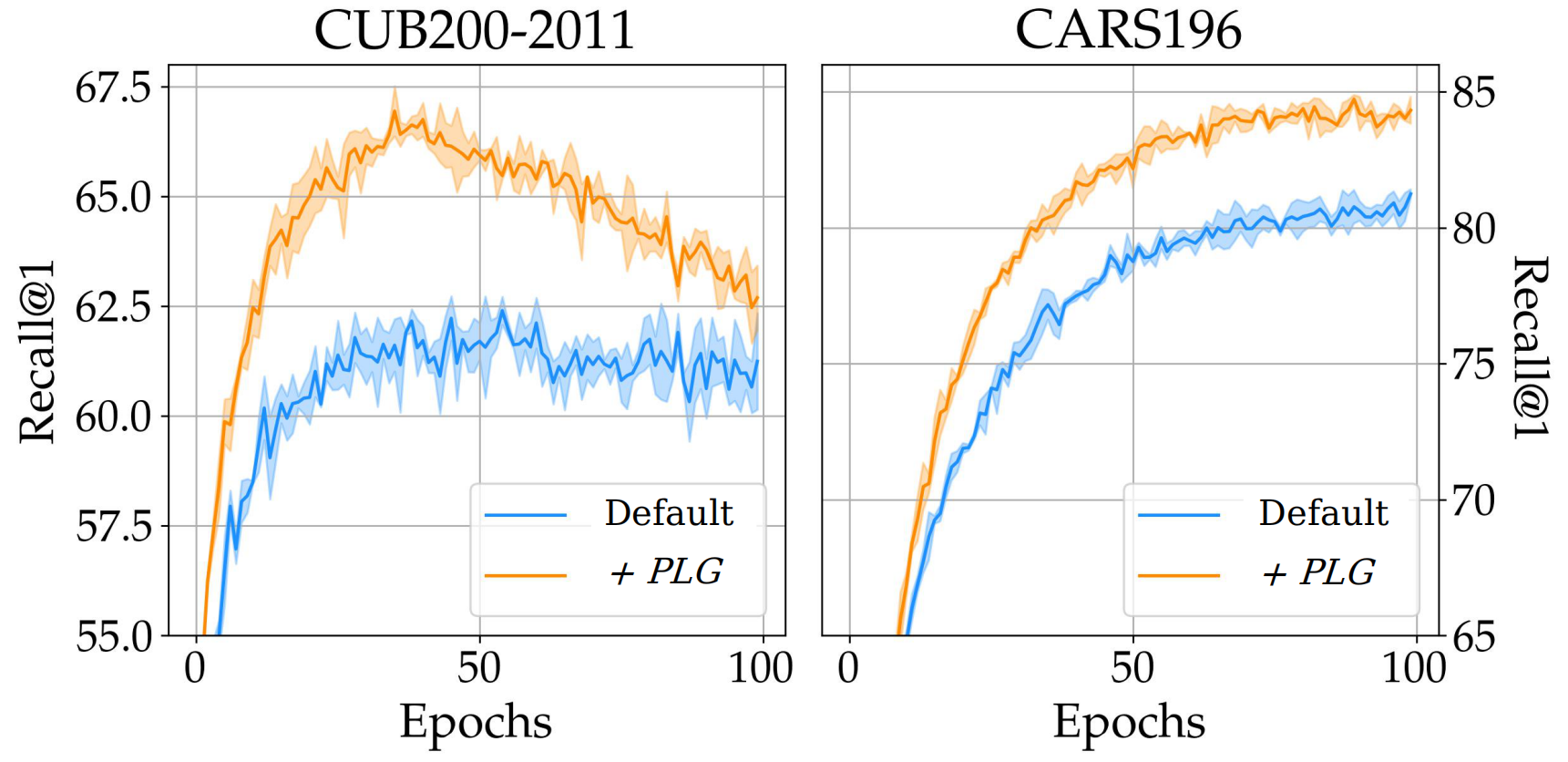
When applying language guidance both with expert labels and with pseudo-labels, we find significant improvements in generalization performance:
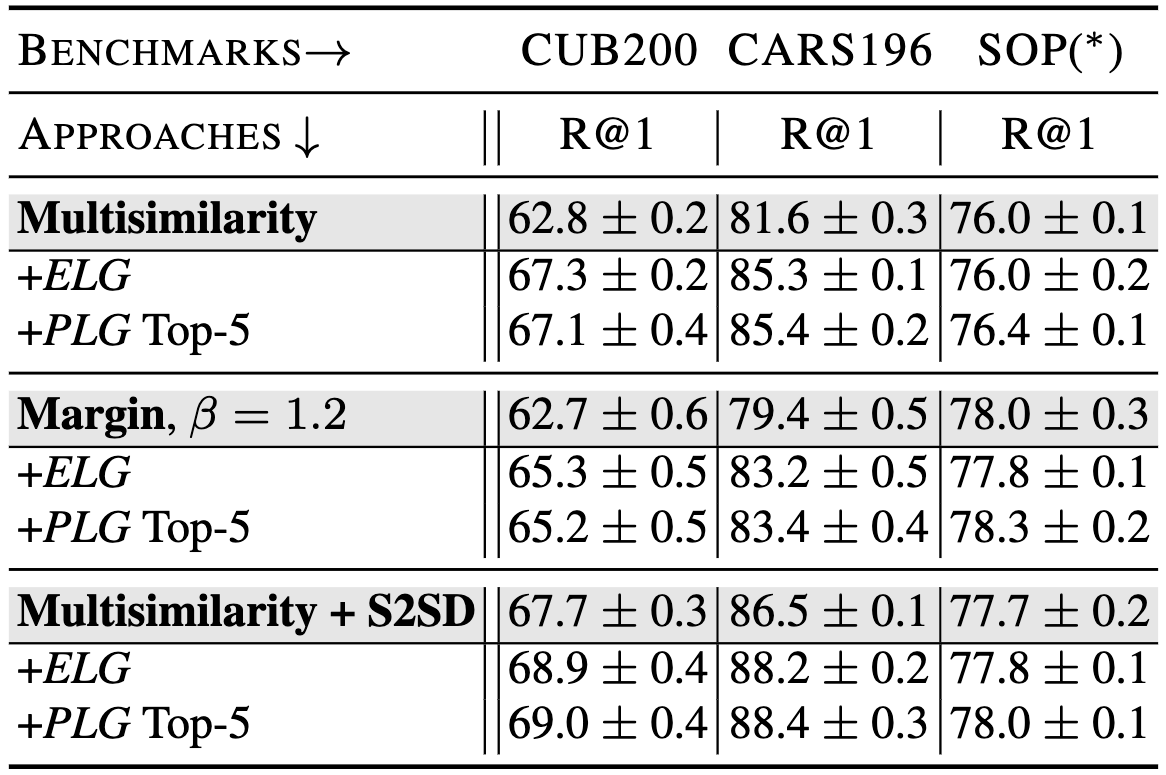
As the results show, performance are majorily increased for strong baseline objectives as well as for already heavily regularized approaches, supporting the notable benefits of language-guidance for visual similarity systems and our proposed method as a strong proof-of-concept.
In addition to that, as all language embeddings are computed with a single forward pass over the training dataset , impact on training time is minimal, with training convergence in parts even speeding up.
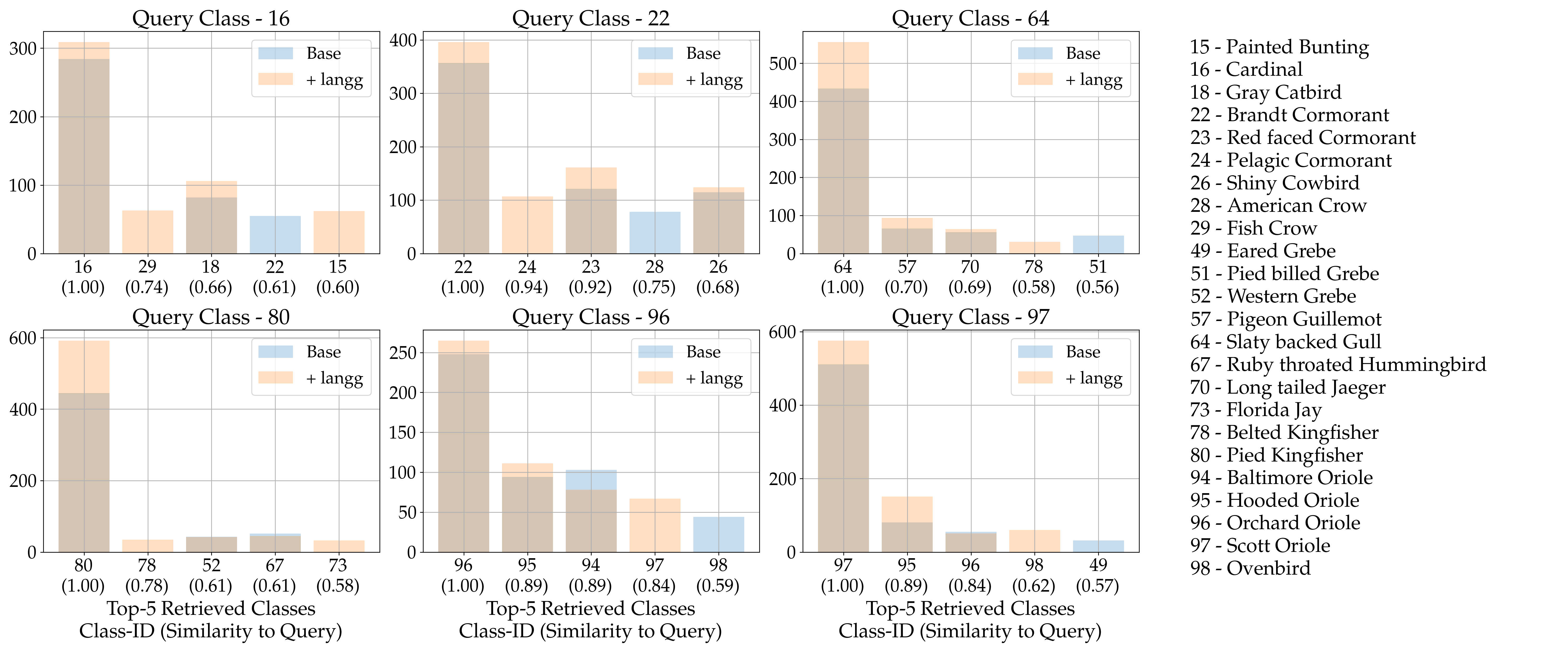
Impact on retrieval behaviour
Finally, we also find that language-guided models are on average more likely to retrieve from semantically related classes than those without language-guidance.
For even more ablations and evaluations of our proposed approach, we refer to out paper.