
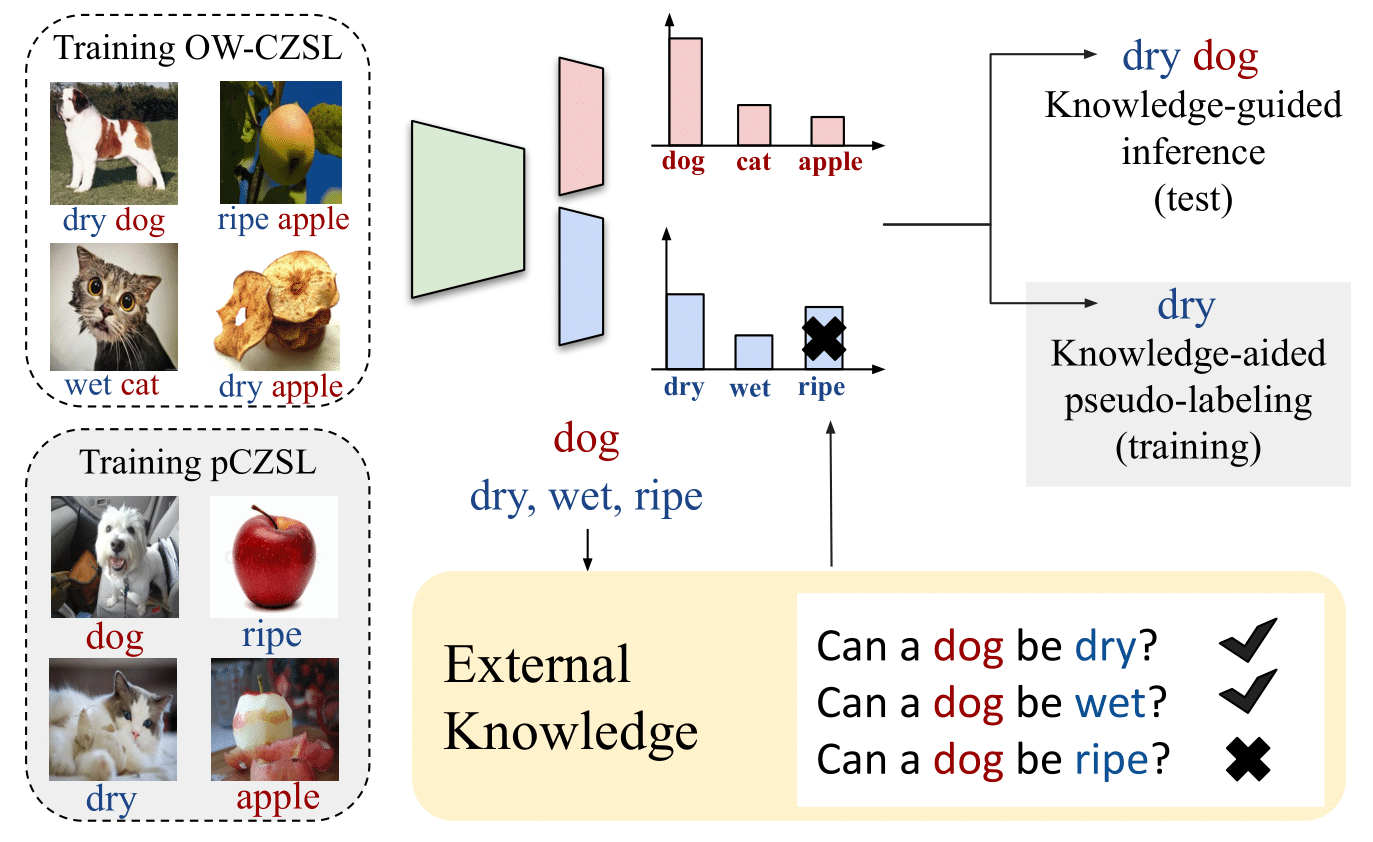
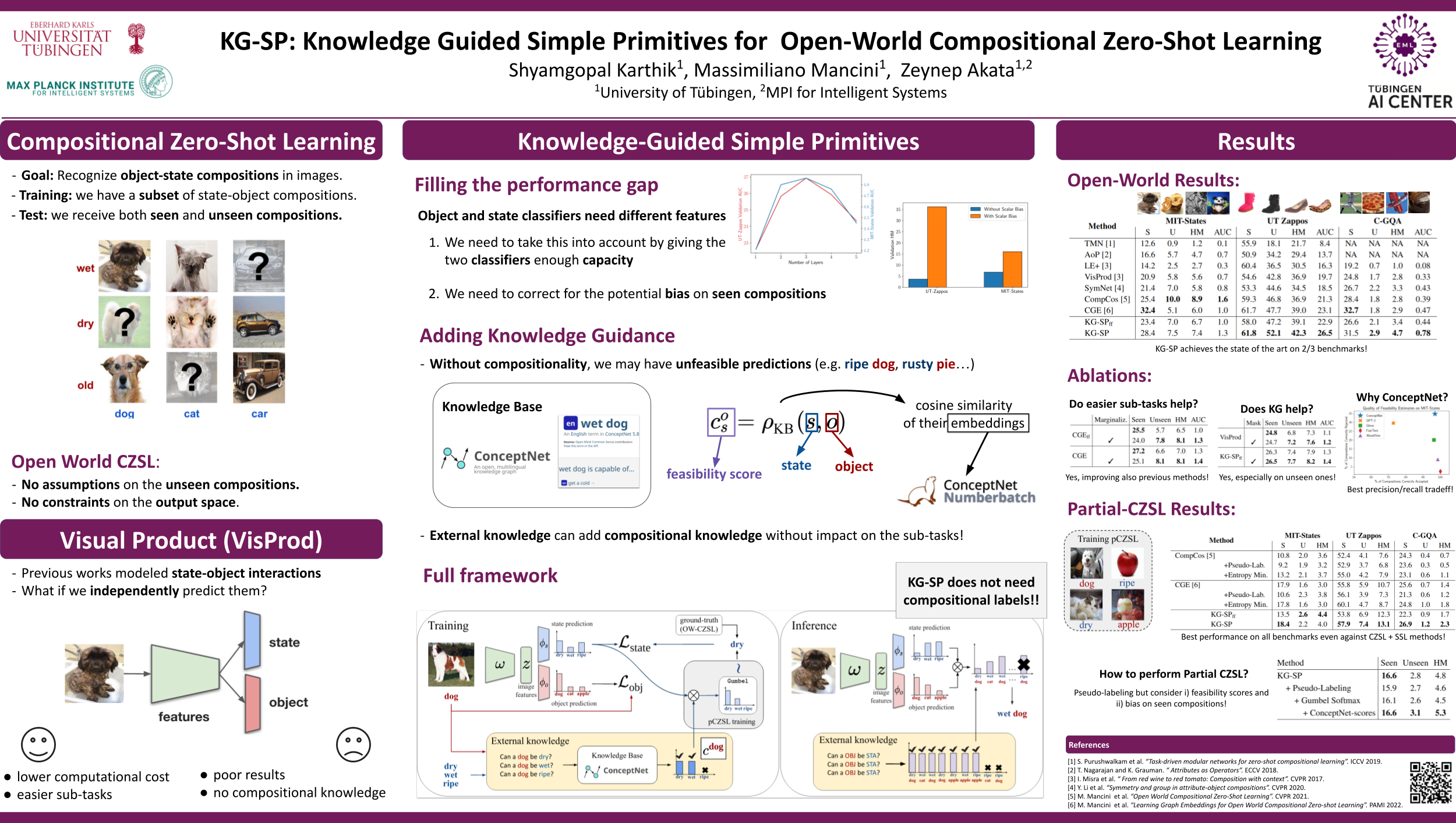
The goal of open-world compositional zero-shot learning (OW-CZSL) is to recognize compositions of state and objects in images, given only a subset of them during training and no prior on the unseen compositions. In this setting, models operate on a huge output space, containing all possible state-object compositions. While previous works tackle the problem by learning embeddings for the compositions jointly, here we revisit a simple CZSL baseline and predict the primitives, i.e. states and objects, independently. To ensure that the model develops primitive-specific features, we equip the state and object classifiers with separate, non-linear feature extractors. Moreover, we estimate the feasibility of each composition through external knowledge, using this prior to remove unfeasible compositions from the output space. Finally, we propose a new setting, i.e. CZSL under partial supervision (pCZSL), where either only objects or state labels are available during training and we can use our prior to estimate the missing labels. Our model, Knowledge-Guided Simple Primitives (KG-SP), achieves the state of the art in both OW-CZSL and pCZSL, surpassing most recent competitors even when coupled with semi-supervised learning techniques.
Introduction
Compositional Zero-Shot Learning (CZSL) is the task of predicting the object (e.g. tomato, dog, car) and the state (e.g. wet, dry, pureed) present in a given input image. The challenge in this task is to be able to generalize to the unseen compositions of states and objects. Recently, multiple works tackled this problem from different perspectives, usually modeling the interactions between the states and objects. Examples are modeling attributes as operators modifying object representations, predicting embeddings for each composition through simple multi-layer perceptrons or graph convolutions, or modeling the dependency between object and state representations from a causal perspective.
Approach
In this work, we take a step back and ask what happens if we independnetly preidct states and objects. While this approach is quite efficient computationally, it could introduce the issue of predicting infeasible compositions (i.e ripe dog). We address this issue by introducing external knowledge into the model. To do this, we resort to the ConceptNet knowledge base. We extract the ConceptNet NumberBatch embeddings for all the state and object primitives and compute their similarity. Based on this, we are able to determine feasible and infeasible compositions through thresholding. During inference, we apply this as a hard mask over the predictions.
An additional benefit of this approach of independently predicting states and objects is that we do not require compositional labels (i.e the samples can be labeled with either the object or state label). To explore this further, we introduce the partial CZSL (pCZSL) setting where all the samples have either the state or object label, but not both. Here, in addition to using the ConceptNet based as a hard mask during inference, we also use the feasibility scores as a source of pseudo-labels to further enhance the performance. Our entire model for this setup is shown below:
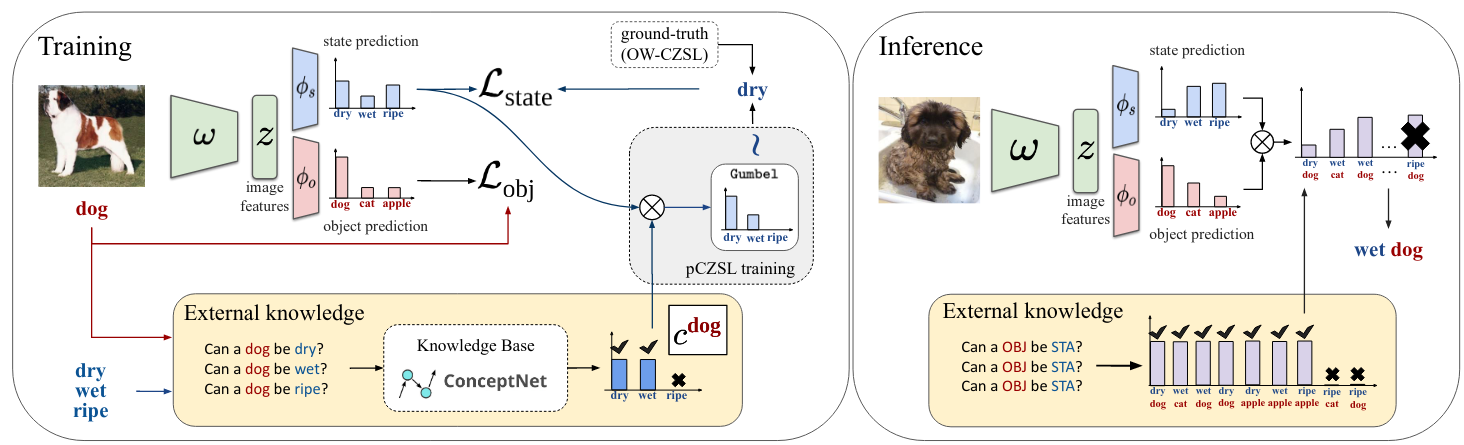
Results
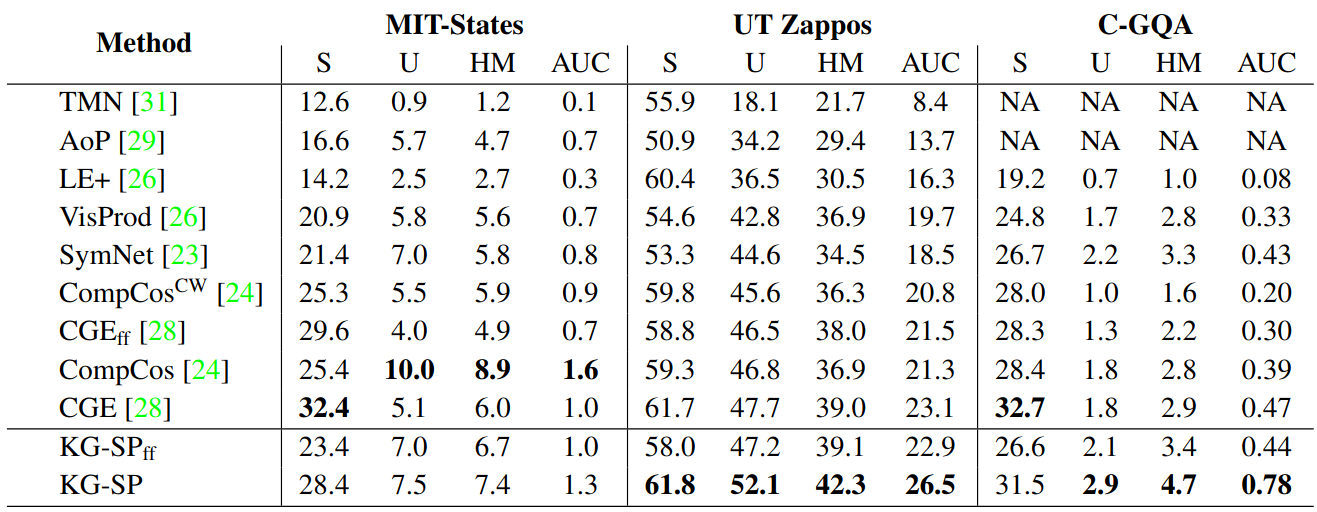
Our model achieves state-of-the-art results on the UT-Zappos and C-GQA datasets in the open-world CZSL setting. The results can be seen below:
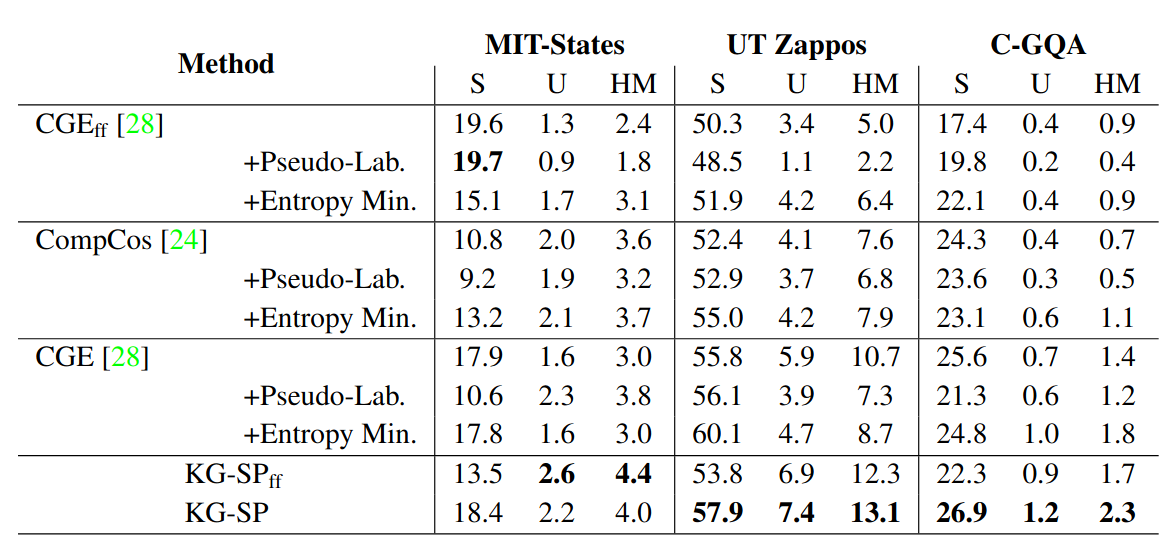
Similarly, on our proposed pCZSL setting, we achieve state-of-the-art results on all the 3 datasets (UT-Zappos, MIT-States, C-GQA).
Here is our poster, which provides an even shorter summary:
For more results and analysis, please refer to the paper.