
Weakly supervised multi-label classification (WSML) task, which is to learn a multi-label classification using partially observed labels per image, is becoming increasingly important due to its huge annotation cost. In this work, we first regard unobserved labels as negative labels, casting the WSML task into noisy multi-label classification. From this point of view, we empirically observe that memorization effect, which was first discovered in a noisy multi-class setting, also occurs in a multi-label setting. That is, the model first learns the representation of clean labels, and then starts memorizing noisy labels. Based on this finding, we propose novel methods for WSML which reject or correct the large loss samples to prevent model from memorizing the noisy label. Without heavy and complex components, our proposed methods outperform previous state-of-the-art WSML methods on several partial label settings including Pascal VOC 2012, MS COCO, NUSWIDE, CUB, and OpenImages V3 datasets. Various analysis also show that our methodology actually works well, validating that treating large loss properly matters in a weakly supervised multi-label classification.
Introduction
In a weakly supervised multi-label classification (WSML) task, labels are given as a form of partial label, which means only a small amount of categories is annotated per image. This setting reflects the recently released large-scale multi-label datasets, e.g. JFT-300M or InstagramNet-1B, which provide only partial label. Thus, it is becoming increasingly important to develop learning strategies with partial labels.
Approach
Target with Assume Negative
Let us define an input and a target where and compose a dataset . In a weakly supervised multi-label learning for image classification task, is an image set and where is an annotation of `unknown', i.e. unobserved label, and is the number of categories. For the target , let , , and . In a partial label setting, small amount of labels are known, thus . We start our method with Assume Negative (AN) where all the unknown labels are regarded as negative. We call this modified target as ,
and the set of all as . and are the set where each element is true positive and true negative, respectively. contains both true negative and false negative. % and are true negative and false negative, respectively. % Therefore, would be either true negative or false negative. % Note that in WSML with AN target, there are no labels with false positive. The naive way of training the model with the dataset is to minimize the loss function ,
where and is the binary cross entropy loss between the function output and the target. We call this naive method as Naive AN.
Memorization effect in WSML
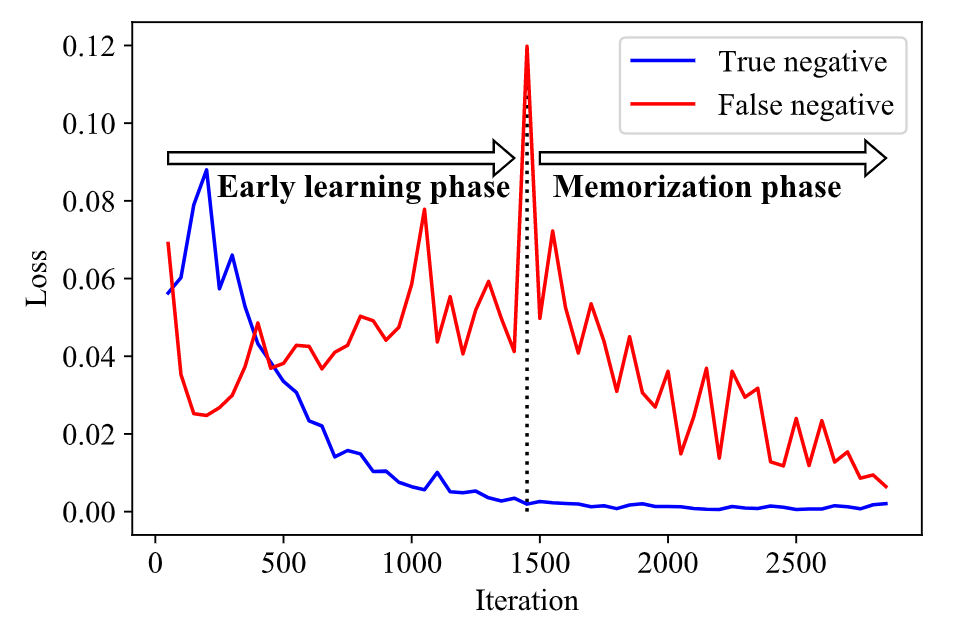
We observe that a memorization effect occurs in WSML when the model is trained with the dataset with AN target. To confirm this, we make the following experimental setting. We convert Pascal VOC 2012 dataset into partial label one by randomly remaining only one positive label for each image and regard other labels as unknown (dataset ). These unknown labels are then assumed as negative (dataset ). We train ResNet-50 model with using the loss function in the equation above. We look at the trend of loss value corresponding to each label in a training dataset while the model is trained. A single example for true negative label and false negative label is shown in the above figure. For a true negative label, the corresponding loss value keeps decreasing as the number of iteration increases (blue line). Meanwhile, the loss of a false negative label slightly increases in the initial learning phase, and then reaches the highest in the middle phase followed by decreasing to reach near at the end (red line). This implies that the model starts to memorize the wrong label from the middle phase.
Method
In this section, we propose novel methods for WSML motivated from the ideas of noisy multi-class learning which ignores the large loss during training the model. Remind that in WSML with AN target, the model starts memorizing the false negative label in the middle of the training with having a large loss at that time. While we can only observe that the label in the set is negative and cannot explicitly discriminate whether it is false or true, we are able to implicitly distinguish between them. It is because the loss from false negative is likely to be larger than the loss from true negative before memorization starts. Therefore, we manipulate the label in the set that corresponds to the large loss value during the training process to prevent the model from memorizing false negative labels. We do not manipulate the known true labels, i.e. , since they are all clean labels. Instead of using the original loss function, we further introduce the weight term in the loss function,
We define where arguments of function , that are and , are omitted for convenience. The term is defined as a function, , where arguments are also omitted for convenience. is the weighted value for how much the loss should be considered in the loss function. Intuitively, should be small when and the loss has high value in the middle of the training, that is, to ignore that loss since it is likely to be the loss from a false negative sample. We set when since the label from these indices is a clean label. We present three different schemes of offering the weight for . The schematic description is shown below.
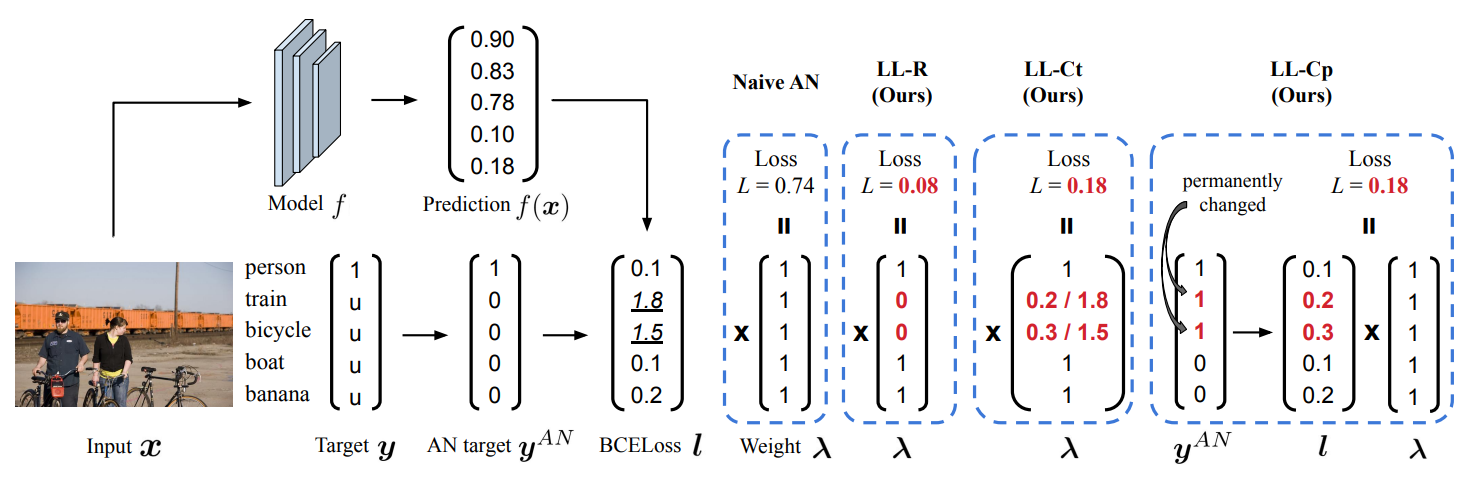
Large Loss Rejection. This is to gradually increase the rejection rate during the training process. We set the function as
where is the number of current epochs in the training process and is the loss value that has largest value in the loss set . is a hyperparameter that determines the speed of increase of rejection rate. Defining as above makes rejecting large loss samples in the loss function. We do not reject any loss values at the first epoch, , since the model learns clean patterns in the initial phase. In practice, we use mini-batch in each iteration instead of full batch for composing the loss set. We call this method as LL-R. We also propose LL-Ct and LL-Cp which refer to large loss correction (temporary) and large loss correction (permanent), respectively. The readers can find these variants in detail in the paper.
Results

The figure above shows the qualitative result of LL-R. The arrow indicates the change of categories with positive labels during training and GT indicates actual ground truth positive labels for a training image. We see that although not all ground truth positive labels are given, our proposed method progressively corrects the category of unannotated GT as positive. We also observe in the first three columns that a category that has been corrected once continues to be corrected in subsequent epochs, even though we perform correction temporarily for each epoch. This conveys that LL-R successfully keeps the model from memorizing false negatives. We also report the failure case of our method on the rightmost side where the model confuses the car as truck which is a similar category and misunderstands the absent category person as present. The quantitative comparison and more analysis of our method can be found in the paper.