

Human-annotated attributes serve as powerful semantic embeddings in zero-shot learning. However, their annotation process is labor-intensive and needs expert supervision. Current unsupervised semantic embeddings, i.e., word embeddings, enable knowledge transfer between classes. However, word embeddings do not always reflect visual similarities and result in inferior zero-shot performance. We propose to discover semantic embeddings containing discriminative visual properties for zero-shot learning, without requiring any human annotation. Our model visually divides a set of images from seen classes into clusters of local image regions according to their visual similarity, and further imposes their class discrimination and semantic relatedness. To associate these clusters with previously unseen classes, we use external knowledge, e.g., word embeddings and propose a novel class relation discovery module. Through quantitative and qualitative evaluation, we demonstrate that our model discovers semantic embeddings that model the visual properties of both seen and unseen classes. Furthermore, we demonstrate on three benchmarks that our visually-grounded semantic embeddings further improve performance over word embeddings across various ZSL models by a large margin.
Introduction
Semantic embeddings aggregated for every class live in a vector space that associates different classes, even when visual examples of these classes are not available. Therefore, they facilitate the knowledge transfer in zero-shot learning (ZSL) and are used as side-information in other computer vision tasks like fashion trend forecast, face recognition and manipulation. Human annotated attributes are widely used semantic embeddings. However, obtaining attributes is often a labor-intensive process. Previous work tackle this problem by using word embeddings for class names, or semantic embeddings from online encyclopedia articles. However, some of these relations may not be visually detectable by machines, resulting in a poor performance in zero-shot learning.
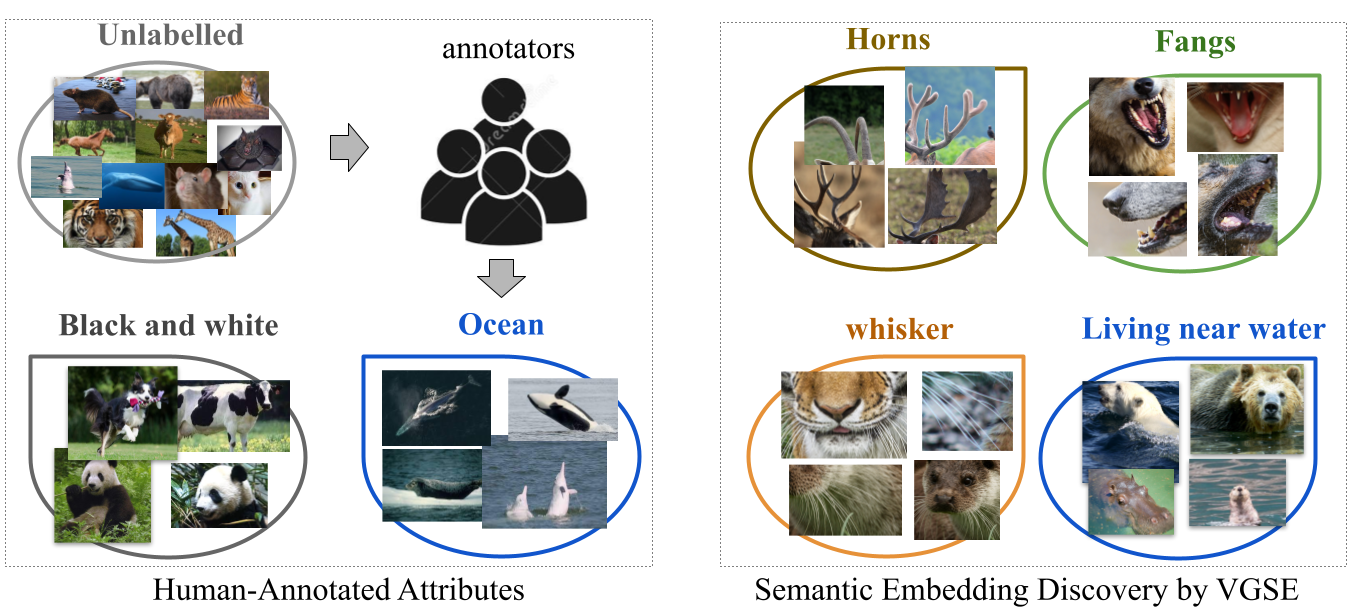
To this end, we propose the Visually-Grounded Semantic Embedding (VGSE) Network to discover semantic embeddings with minimal human supervision (we only use category labels for seen class images). To fully unearth the visual properties shared across different categories, our model discovers semantic embeddings by assigning image patches into various clusters according to their visual similarity. Besides, we further impose class discrimination and semantic relatedness of the semantic embeddings, to benefit their ability in transferring knowledge between classes in ZSL.
Model
Notations
We are interested in the (generalized) zero-shot learning task where the training and test classes are disjoint sets. The training set consists of images and their labels from the seen classes . In the ZSL setting, test images are classified into unseen classes , and in the GZSL setting, into both and with the help of a semantic embedding space. We propose to automatically discover a set of visual clusters as the semantic embedding, denoted by . The semantic embeddings for seen classes , describing diverse visual properties of each category, are learned on seen classes images . The semantic embeddings for unseen classes is predicted with the help of unsupervised word embeddings, e.g., w2v embeddings for class names .
Our Visually-Grounded Semantic Embedding(VGSE) Network consists of two main modules. (1) The Patch Clustering module takes the training dataset as input, and clusters the image patches into visual clusters. (2) The Class Relation module to infer the semantic embeddings of unseen classes.
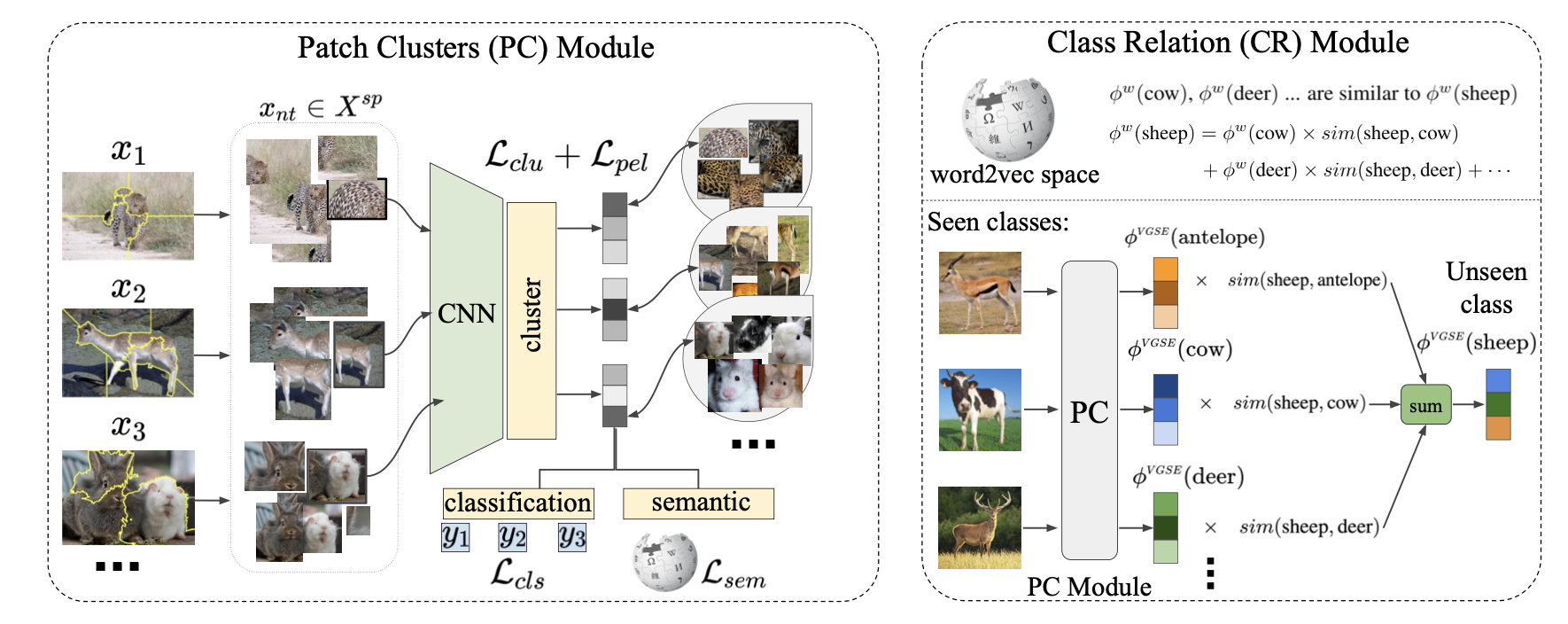
Patch clustering module
Each image is cropped into patches that cover different parts of the image. In this way, we reconstruct our training set consisting of image patches . Our patch clustering module is a differentiable middle layer, that simultaneously learns image patch representations and clustering.
We start from a deep neural network that extracts patch feature . Afterwards, a clustering layer converts the feature representation into cluster scores:
where (the -th element of ) indicates the probability of assigning image patch to cluster , e.g., the patch clusters of spotty fur, fluffy head, etc.
To impose class discrimination information into the learnt clusters, we apply an cluster-to-class layer to map the cluster prediction of each image to the class probability, i.e., , and train this module with cross-entropy loss:
We further encourage the learned visual clusters to be transferable between classes. We implement this by mapping the learned cluster probability to the semantic space constructed by w2v embeddings . The cluster-to-semantic layer is trained by regressing the w2v embedding for each class,
where denotes the ground truth class, and represents the w2v embedding for the class .
The image embedding for is calculated by averaging the patch embedding in that image: . We calculate the semantic embedding for by averaging the embeddings of images belonging to :
Class relation module
While seen semantic embeddings can be estimated from training images using, how to compute the unseen semantic embeddings is not straightforward since their training images are not available. Given the w2v embeddings of seen classes and embedding for unseen class , we learns a similarity mapping , where denotes the similarity between the unseen class and the -th seen class. The similarity mapping is learned via the following optimization problem:
After the mapping is learned, we can predict the semantic embeddings for the unseen class as: where the value of each discovered semantic embedding for unseen class is the weighted sum of all seen class semantic embeddings. Finally, the learned semantic embedding can be used to perform downstream tasks, e.g., Zero-Shot Learning.
Visually-grounded semantic embeddings
We show the 2D visualization of image patches in the AWA2, where image patches are presented by projecting their embeddings onto two dimensions with t-SNE. To picture the distribution of the semantic embedding space, we sample several visual clusters~(dots marked in the same color) and the image patches from the cluster center of both seen and unseen categories.
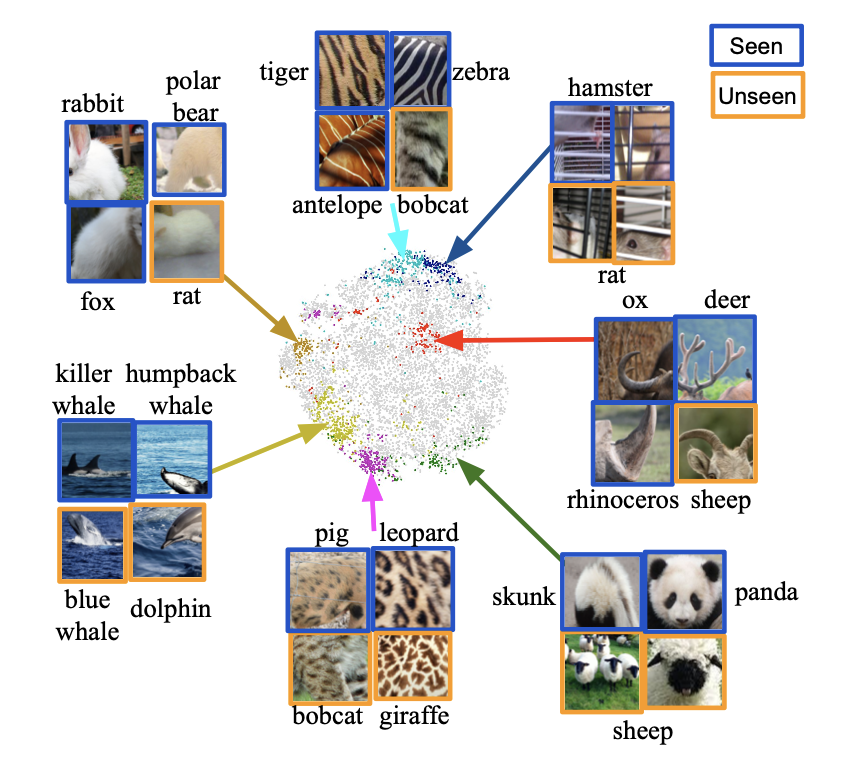
We observe that samples in the same cluster tend to gather together, indicating that the embeddings provide discriminative information. Besides, images patches in one cluster do convey consistent visual properties, though coming from disjoint categories. For instance, the white fur appears on rabbit, polar bear, and fox are clustered into one group. We further observe that nearly all clusters consist images from more than one categories. It indicates that the clusters we learned contain semantic properties shared across seen classes, and can be transferred to unseen classes. Another interesting observation is that our VGSE clusters discover visual properties that may be neglected by human-annotated attributes, e.g., the cage appear for hamsters and rat.
For more quantitative results, please refer to the paper.