

Any-shot image classification allows to recognize novel classes with only a few or even zero samples. For the task of zero-shot learning, visual attributes have been shown to play an important role, while in the few-shot regime, the effect of attributes is under-explored. To better transfer attribute-based knowledge from seen to unseen classes, we argue that an image representation with integrated attribute localization ability would be beneficial for any-shot, i.e. zero-shot and few-shot, image classification tasks. To this end, we propose a novel representation learning framework that jointly learns discriminative global and local features using only class-level attributes. While a visual-semantic embedding layer learns global features, local features are learned through an attribute prototype network that simultaneously regresses and decorrelates attributes from intermediate features. Furthermore, we introduce a zoom-in module that localizes and crops the informative regions to encourage the network to learn informative features explicitly. We show that our locality augmented image representations achieve a new state-of-the-art on challenging benchmarks, i.e. CUB, AWA2, and SUN. As an additional benefit, our model points to the visual evidence of the attributes in an image, confirming the improved attribute localization ability of our image representation. The attribute localization is evaluated quantitatively with ground truth part annotations, qualitatively with visualizations, and through well-designed user studies.
Introduction
Visual attributes have been shown to be important for zero- and few-shot learning, i.e. any-shot learning, as they allow semantic knowledge transfer from known classes with abundant training samples to novel classes with only a handful of images. We argue that any-shot learning can significantly benefit from an image representation that allows localizing visual attributes in images, especially for fine-grained scenarios where local attributes are critical to distinguish two similar categories. In this work, we refer to the ability of an image representation to localize and associate an image region with a visual attribute as locality. Our goal is to improve the locality of image representations for any-shot learning.
We develop a weakly supervised representation learning framework that localizes and decorrelates visual attributes. To achieve this, we learn prototypes in the feature space which define the property for each attribute, at the same time, the local image features are encouraged to be similar to the corresponding attribute prototype. We propose to alleviate the impact of incidentally correlated attributes by leveraging their semantic relatedness while learning these local features. As an additional benefit, our model points to the visual evidence of the attributes in an image, confirming the improved attribute localization ability of our image representation.
Model
Notations
The training set consists of labeled images and attributes from seen classes, i.e. . Here, denotes an image in the RGB image space , is its class label, and is the class embedding. Here we use to denote the unseen class label set in ZSL and the novel class in FSL for convenience. The class embeddings of unseen classes, i.e. , are also known.
The goal for ZSL is to predict the label of images from unseen classes, i.e. , while for generalized ZSL the goal is to predict images from both seen and unseen classes, i.e. . Few-shot learning (FSL) and generalized few-shot learning (GFSL) are defined similarly. The main difference lies that instead of only knowing the attributes of novel classes in ZSL, FSL also gets a few training samples from each novel class.
In the following, we describe our end-to-end trained attribute prototype network (APN). There are three modules in our framework, the base module, the prototype module, and the Zoom-In Module.
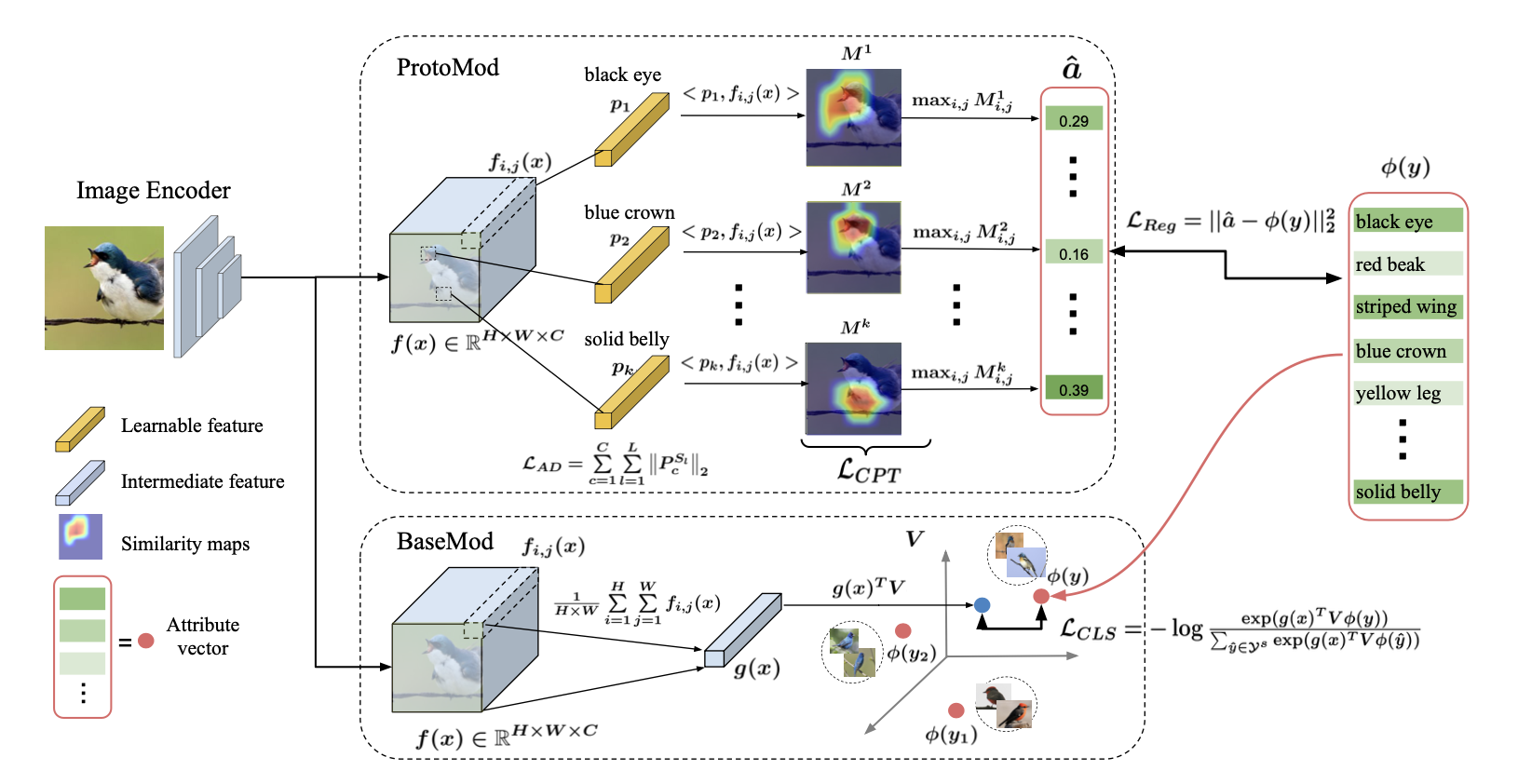
Base Module for global feature learning
The base module (BaseMod) learns discriminative visual features for classification. Given an input image , the Image Encoder converts it into a feature representation where , and denote the height, width, and channel respectively. Base module then applies global average pooling over the and to learn a global discriminative feature :
A linear layer with parameter maps the visual feature into the class embedding~(e.g. attribute) space. The dot product between the projected visual feature and every class embedding is computed to produce class logits , followed by the cross-entropy loss encouraging the image to have a high compatibility score with its corresponding attribute vector:
where , . The visual-semantic embedding layer and the CNN backbone are optimized jointly to finetune the image representation guided by the attribute vectors.
Prototype module for local feature learning
Prototype module takes as input the feature where the local feature at spatial location encodes information of local image regions. Then we learn a set of attribute prototypes to predict attributes from those local features, where denotes the prototype for the -th attribute. For each attribute, we produce a similarity map where each element is computed by a dot product between the attribute prototype and each local feature, i.e. . Afterwards, we predict the -th attribute by taking the maximum value in the similarity map :
We consider the attribute prediction task as a regression problem and minimize the Mean Square Error~(MSE) between the ground truth attributes and the predicted attributes :
Visual attributes are often correlated with each other as they frequently co-occur. Therefore, we propose to constrain the attribute prototypes by encouraging feature competition among unrelated attributes and feature sharing among related attributes. We divide all attributes into disjoint groups, encoded as sets of attribute indices , then adopt the attribute decorrelation loss:
In addition, we apply the following compactness regularizer on each similarity map , to constrain the similarity map such that it concentrates on its peak region rather than disperses on other locations:
Zoom-In module for attribute prototype-informed feature learning
We propose a Zoom-In Module to highlight the image regions covered by the informative attribute similarity maps and discard the irrelevant image regions. We first sum up the attribute similarity maps for the most informative attribute in each attribute group to form the attention map :
We binarize the informative attention map with the average attention value to form a mask :
The binary mask is upsampled to the size of the input image, and we use the smallest bounding box covering the non-zero area to crop the original image.
Attribute localization results
We first investigate the difference between our APN and the base module (BaseMod) for localizing different body parts in CUB dataset. The result is shown in the following figure.
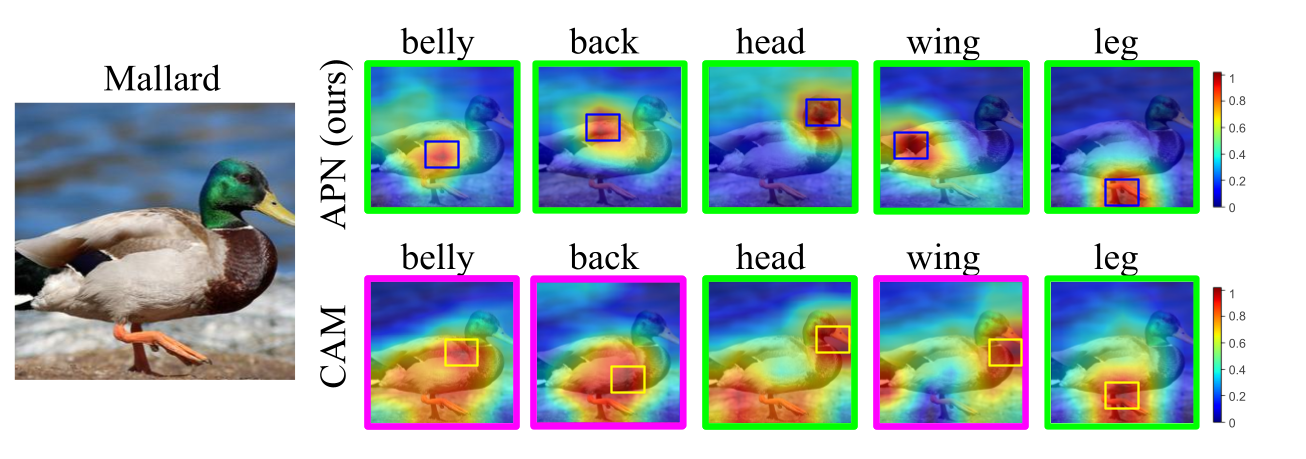
For each part of the bird Mallard, we display one attribute similarity map generated by our model APN, and the BaseMod visualized by CAM. The baseline model tends to generate disperse attention maps covering the whole bird, as it utilizes more global information, e.g. correlated bird parts and context, to predict attributes. On the other hand, the similarity maps of our APN are more concentrated and diverse and therefore they localize different bird body parts more accurately. The improvement is lead by the attribute prototypes and compactness loss, which helps the model to focus on local image features when learning attributes.
In the following Figure, we compare our APN model with two baseline models on AWA2 and SUN. The attribute attention maps of BaseMod is generated with two gradient-based visual explanation method CAM and Grad-CAM.
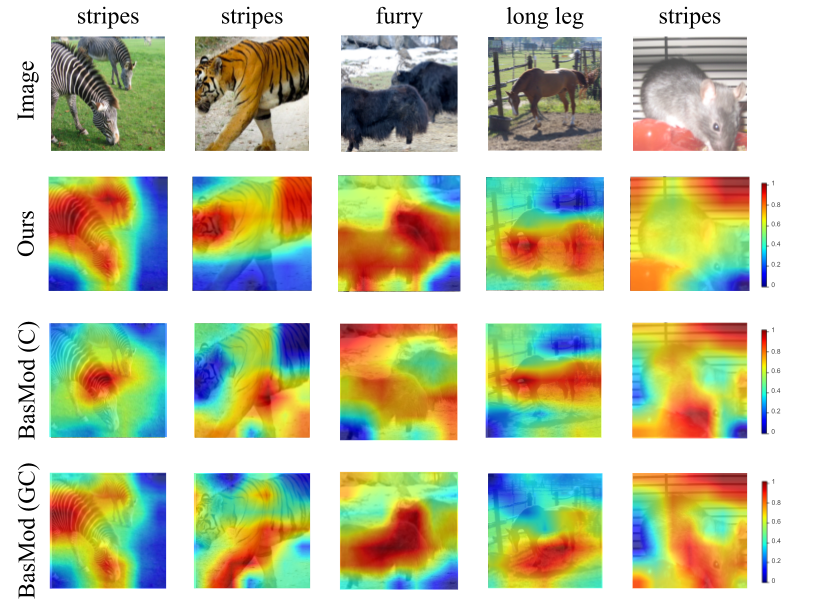
Our network produces precise similarity maps for visual attributes that describe texture and body parts, etc. We can localize visual attributes with diverse appearances, e.g. the white and black stripe of zebra, and the yellow and black stripe of tiger (row 2, column 3,4), while CAM and Grad-CAM fails in localizing the stripe on tigers.
Our similarity maps for furry and longleg can precisely mask out the image regions of the ox and horse (row 2, column 3,4), while BaseMod only localizes part of the image (row 1, column 3,4). In AWA2 dataset we are interested in the visual attributes of animals, while our model in some cases highlights the attributes of the background, e.g. identifying the grid on the rat cage as stripes (row 2, column 5). This can be explained by the fact that our model only relies on weak supervision, i.e. class-level attributes and their semantic relatedness.
For more results and analysis, please refer to the paper.