
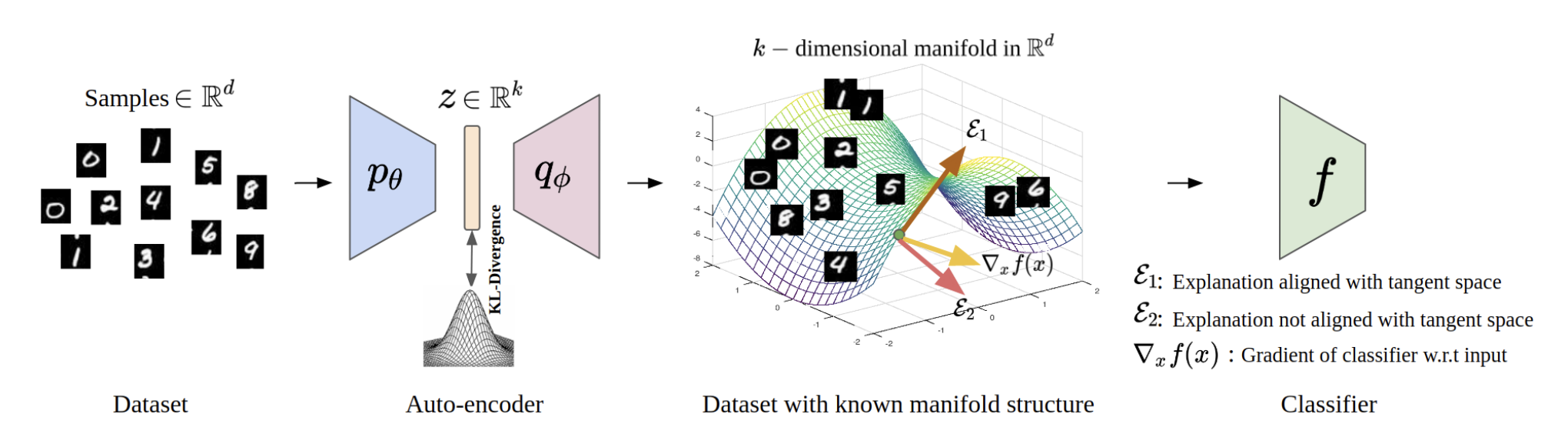
When do gradient-based explanation algorithms provide perceptually-aligned explanations? We propose a criterion - the feature attributions need to be aligned with the tangent space of the data manifold. To provide evidence for this hypothesis, we introduce a framework based on variational autoencoders that allows to estimate and generate image manifolds. Through experiments across a range of different datasets – MNIST, EMNIST, CIFAR10, X-ray pneumonia and Diabetic Retinopathy detection – we demonstrate that the more a feature attribution is aligned with the tangent space of the data, the more perceptually-aligned it tends to be. We then show that the attributions provided by popular post-hoc methods such as Integrated Gradients and SmoothGrad are more strongly aligned with the data manifold than the raw gradient. Adversarial training also improves the alignment of model gradients with the data manifold. As a consequence, we suggest that explanation algorithms should actively strive to align their explanations with the data manifold. An extended version of this paper is available at https://arxiv.org/abs/2206.07387.
Abstract
When do gradient-based explanation algorithms provide perceptually-aligned explanations? We propose a criterion - the feature attributions need to be aligned with the tangent space of the data manifold. To provide evidence for this hypothesis, we introduce a framework based on variational autoencoders that allows to estimate and generate image manifolds. Through experiments across a range of different datasets – MNIST, EMNIST, CIFAR10, X-ray pneumonia and Diabetic Retinopathy detection – we demonstrate that the more a feature attribution is aligned with the tangent space of the data, the more perceptually-aligned it tends to be. We then show that the attributions provided by popular post-hoc methods such as Integrated Gradients and SmoothGrad are more strongly aligned with the data manifold than the raw gradient. Adversarial training also improves the alignment of model gradients with the data manifold. As a consequence, we suggest that explanation algorithms should actively strive to align their explanations with the data manifold. An extended version of this paper is available at https://arxiv.org/abs/2206.07387.