
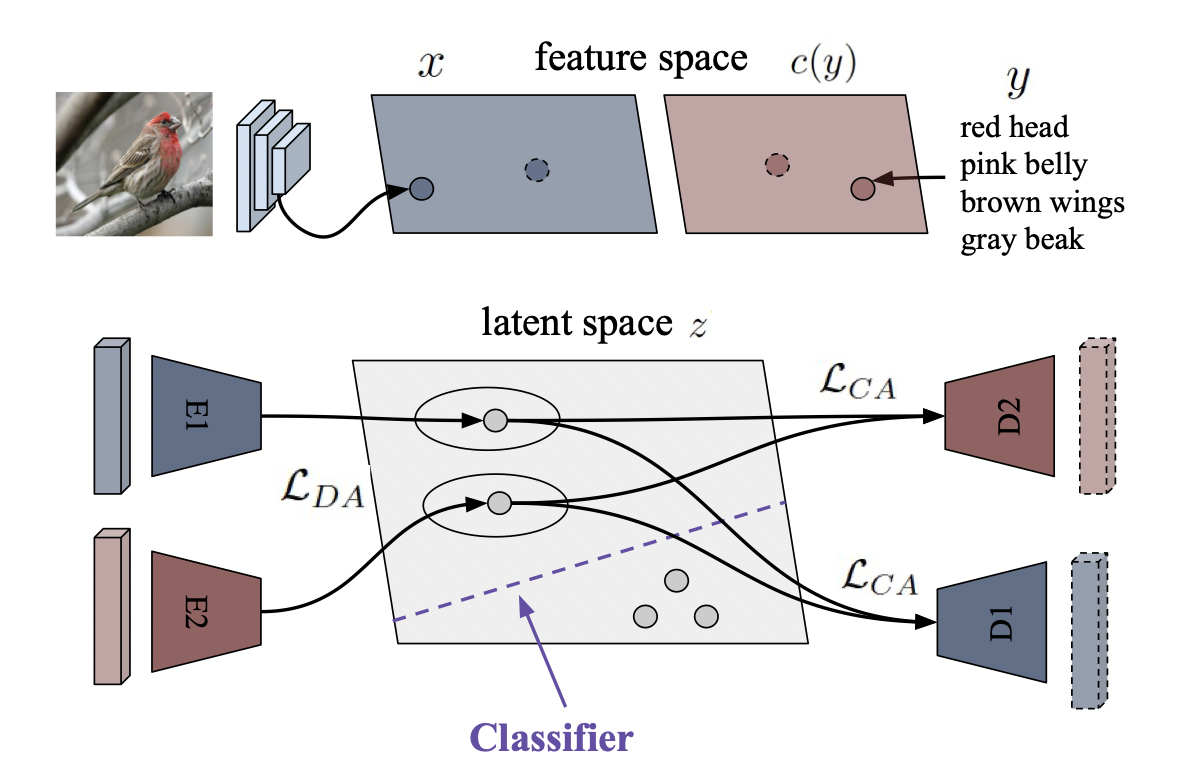
Many approaches in generalized zero-shot learning rely on cross-modal mapping between the image feature space and the class embedding space. As labeled images are expensive, one direction is to augment the dataset by generating either images or image features. However, the former misses fine-grained details and the latter requires learning a mapping associated with class embeddings. In this work, we take feature generation one step further and propose a model where a shared latent space of image features and class embeddings is learned by modality-specific aligned variational autoencoders. This leaves us with the required discriminative information about the image and classes in the latent features, on which we train a softmax classifier. The key to our approach is that we align the distributions learned from images and from side-information to construct latent features that contain the essential multi-modal information associated with unseen classes. We evaluate our learned latent features on several benchmark datasets, i.e. CUB, SUN, AWA1 and AWA2, and establish a new state of the art on generalized zero-shot as well as on few-shot learning. Moreover, our results on ImageNet with various zero-shot splits show that our latent features generalize well in large-scale settings.