

The class activation mapping, or CAM, has been the cornerstone of feature attribution methods for multiple vision tasks. Its simplicity and effectiveness have led to wide applications in the explanation of visual predictions and weakly-supervised localization tasks. However, CAM has its own shortcomings. The computation of attribution maps relies on ad-hoc calibration steps that are not part of the training computational graph, making it difficult for us to understand the real meaning of the attribution values. In this paper, we improve CAM by explicitly incorporating a latent variable encoding the location of the cue for recognition in the formulation, thereby subsuming the attribution map into the training computational graph. The resulting model, class activation latent mapping, or CALM, is trained with the expectation-maximization algorithm. Our experiments show that CALM identifies discriminative attributes for image classifiers more accurately than CAM and other visual attribution baselines.
Long Summary
In this paper, we focus on the class activation mapping (CAM) method, which has been the cornerstone of the feature attribution research. It answers "which pixels are responsible for the prediction" for CNN models. Overview of CAM is...
- CAM works great! Examples in youtube.
- CAM has inspired 5000+ papers in ML and CV!
- CAM also works great for weakly supervised object localization (WSOL) tasks. ref
BUT, there is a remaining weakness for CAM
- Explaining the value of CAM in human language is difficult to understand.
"The pixel-wise pre-GAP, pre-softmax feature value at (h, w), measured in relative scale within the range of Values [0, A] where A is the maximum of the feature values in the entire image"
- In a technical manner, CAM applies normalization on the score map only at test time but not at training time.
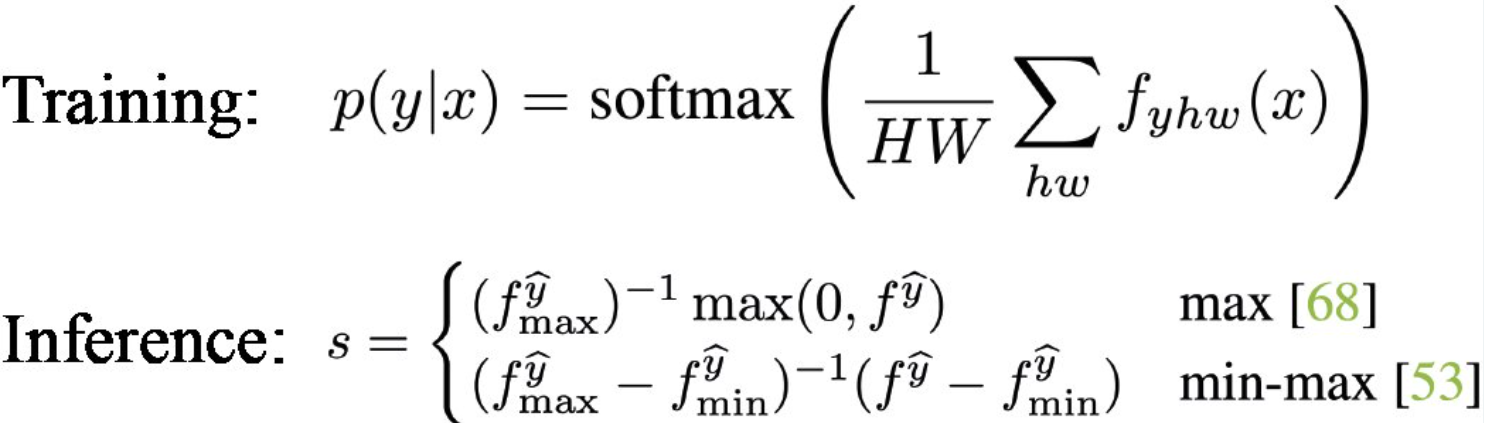
HERE is where we address these issues using probabilistic ML. A good way to normalize something is to use probabilities.
- Probabilistic ML starts with definitions for random variables.
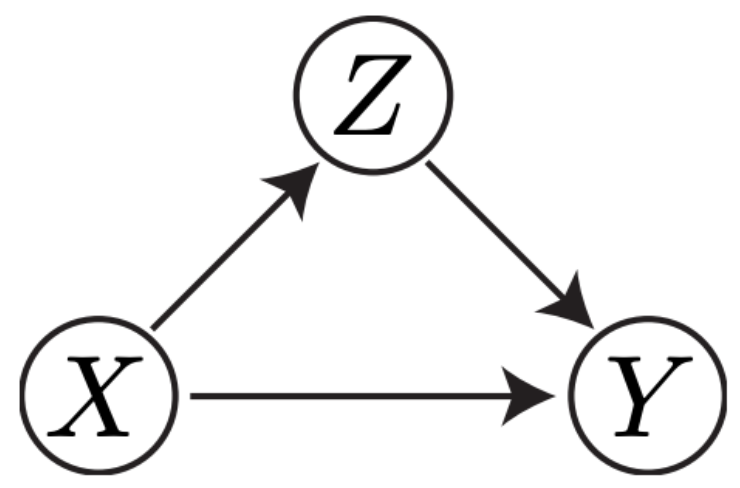
- (X,Y) are usual variables for (image, label).
- Now, a new latent, unobserved variable Z is introduced:
Z = pixel index responsible for the prediction of X as Y - We factorize: p(X,Y,Z) = p(Y|X,Z) p(Z|X) p(X)
- Use probabilistic ML tools for learning with latent variables,
- Marginal likelihood loss: L = - log ∫ p(Y|X,Z) p(Z|X) dZ
- Expectation-Maximization: L = - ∫ p’(Y,Z|X) log p(Y,Z|X)
- Marginal likelihood loss: L = - log ∫ p(Y|X,Z) p(Z|X) dZ
- The resulting p(Y=y, Z|X=x) is the CALM attribution map.
CALM has several benefits.
- Interpretaion-phase computational graph is part of training graph.
- Intuitive description of the CALM attribution map values.
"The probability that the cue for recognition was at position z when the image x is predicted as y"
- Diverse explanation is possible. (s(y) = p(Y=y, Z | X))
- CALM is qualitatively better than CAM. Quantitative results are also better where results are in the paper.


One Caveat is....
- reduced accuracy. For ResNet50 on ImageNet, the top-1 accuracies are 74.5% and 70.5% for CAM and CALM, respectively.
- But this is the classic interpretability-accuracy trade-off.
- In certain applications, you may sacrifice 4/100 predictions for plainly better explainability.
In conclusion, Keep CALM and improve your visual feature attribution!