
Proxy-based Deep Metric Learning (DML) learns deep representations by embedding images close to their class representatives (proxies), commonly with respect to the angle between them. However, this disregards the embedding norm, which can carry additional beneficial context such as class- or image-intrinsic uncertainty. In addition, proxy-based DML struggles to learn class-internal structures. To address both issues at once, we introduce non-isotropic probabilistic proxy-based DML. We model images as directional von Mises-Fisher (vMF) distributions on the hypersphere that can reflect image-intrinsic uncertainties. Further, we derive non-isotropic von Mises-Fisher (nivMF) distributions for class proxies to better represent complex class-specific variances. To measure the proxy-to-image distance between these models, we develop and investigate multiple distribution-to-point and distribution-to-distribution metrics. Each framework choice is motivated by a set of ablational studies, which showcase beneficial properties of our probabilistic approach to proxy-based DML, such as uncertainty-awareness, better-behaved gradients during training, and overall improved generalization performance. The latter is especially reflected in the competitive performance on the standard DML benchmarks, where our approach compares favorably, suggesting that existing proxy-based DML can significantly benefit from a more probabilistic treatment.
From points to distributions
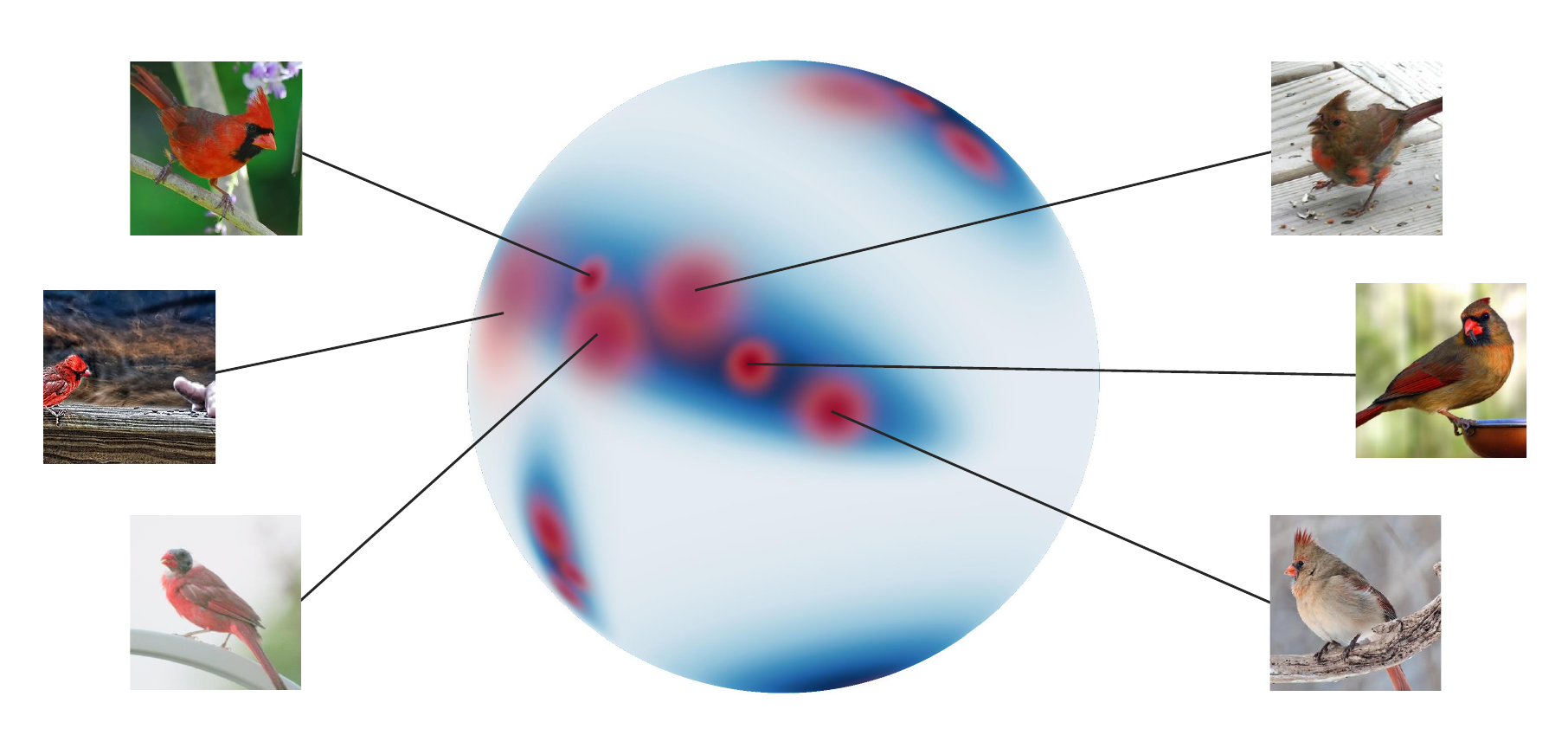
Deep Metric Learning (DML) is concerned with learning an encoder that casts images into embeddings in such a way that their semantic similarity to another image or a class proxy can be measured via, e.g., the cosine distance. Most current works treat these embeddings as points in the embedding space, and, by relying on the cosine distance, disregard the norm of those embeddings. However, recent works indicated that the norm of the embeddings might indicate how many class-relevant features an encoder detected in an image: A very clear image may have many features pointing into the same direction and thus a high norm, whereas an image with less or conflicting information has a lower norm. Therefore, the norm may give a natural estimation of the image's ambiguity and the encoder's certainty.
Hence, instead of seeing embeddings as points, we treat them as natural parameters of von Mises-Fisher (vMF) distributions, with the norm encoding the distribution's variance in the embedding space. Further, we develop a non-isotropic von Mises-Fisher (nivMF) distribution to model class distributions in the embedding space that are capable of representing different variances across different latent features. Just as in traditional DML, we need a metric to compare the similarity of these distributions. To this end, we use an expected-likelihood-kernel based distribution-to-distribution metric. This metric gives a scalar similarity value that can be used in any contrastive loss and, in contrast to traditional DML, incorporates uncertainty information. We find that this leads to better-behaved gradients that incorporate certainty-awareness into the training, which ultimately reflects in improved generalization performance on common DML benchmarks.
Three steps to probabilistic Deep Metric Learning
A proxy-based DML method comprises three main parts: A representation of images and class-proxies, a similarity metric between them, and a contrastive loss over the similarities. We treat the image embeddings output by our encoder as the natural parameters of a vMF distribution. This casts each embedding into a distribution on the hyperspherical embedding space . To account for complex intra-class variance structures, we extend the vMF into a non-isotropic vMF distribution for each of the class proxies . These two distributions are compared via the Expected Likelihood (EL) kernel, as shown below. Since we are now back to a scalar similarity value per comparison, we can plug the probabilistic EL distance into a traditional ProxyNCA++ contrastive loss. This completes our ambiguity-aware training. Note that at test-time, we do not compare proxies to images anymore, but images to images. We can again apply the EL kernel, or, for more rapid retrieval and better comparability to the literature, use the cosine similarity between the embeddings. This train-test switch is possible because the normalized embeddings used to calculate the cosine similarity lie at the modes of their respective vMF distributions.

EL-nivMF is on par with the SOTA
We can apply our approach as a standalone objective or add it as a regularizer to another contrastive loss like ProxyAnchor to benefit from the uncertainty-aware training. We observe increased performance in both cases. In the paper, we also compare against a battery of current state-of-the-art DML methods. In an ablation study, we varied the distance metrics (ELK, KL, Bhattacharyya, log-likelihood, and traditional point-to-point metrics) and the (non)-isotropy. We find that both non-isotropy and the probabilistic treatment of images increases the performance. The ELK metric works best in our experiments, and, surprisingly, the distance surpasses the most commonly used cosine distance (as long as cosine is used for test-time retrieval in both cases). To this end, we note that also respects the norm during training, and in fact its distance surface is similar to distribution-to-distribution metrics.

"Norm = Ambiguity" has two roles during training
A foundation of our work is that the image embedding norm reflects the image ambiguity. We find that this holds in qualitative plots that show the images with the lowest and highest norm. Plots on further datasets and plot per class are provided in the paper. To understand how the norm is incorporated into the training, we take an analytical look at its occurrence in the loss gradients. We find that it has two roles: On the one hand, it appears as an image-wise temperature, where more ambiguous images produce more flat similarity distributions. On the other hand, it scales the gradient up and down such that clear images are weighted higher in a batch than ambiguous images. The full analytical results are provided in the paper.
