

Unpaired image-to-image translation refers to learning inter-image-domain mapping without corresponding image pairs. Existing methods learn deterministic mappings without explicitly modelling the robustness to outliers or predictive uncertainty, leading to performance degradation when encountering unseen perturbations at test time. To address this, we propose a novel probabilistic method based on Uncertainty-aware Generalized Adaptive Cycle Consistency (UGAC), which models the per-pixel residual by generalized Gaussian distribution, capable of modelling heavy-tailed distributions. We compare our model with a wide variety of state-of-the-art methods on various challenging tasks including unpaired image translation of natural images, using standard datasets, spanning autonomous driving, maps, facades, and also in medical imaging domain consisting of MRI. Experimental results demonstrate that our method exhibits stronger robustness towards unseen perturbations in test data. Code is released here: https://github.com/ExplainableML/UncertaintyAwareCycleConsistency.
Long Summary
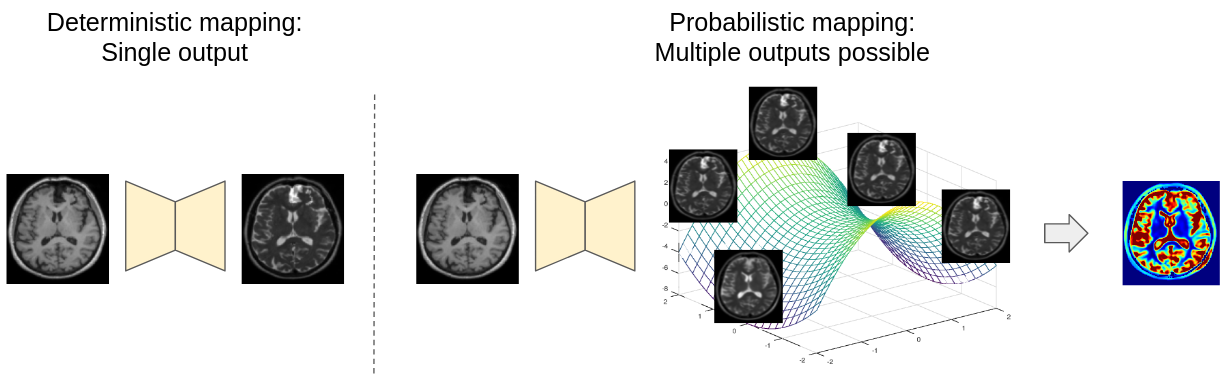
Translating an image from a distribution, i.e. source domain, to an image in another distribution, i.e. target domain, with a distribution shift is an ill-posed problem as a unique deterministic one-to-one mapping may not exist between the two domains. Furthermore, since the correspondence between inter-domain samples may be missing, their joint-distribution needs to be inferred from a set of marginal distributions. However, as infinitely many joint distributions can be decomposed into a fixed set of marginal distributions, the problem is ill-posed in the absence of additional constraints. Image translation approaches often learn a deterministic mapping between the domains where every pixel in the input domain is mapped to a fixed pixel value in the output domain. However, such a deterministic formulation can lead to mode collapse while at the same time not being able to quantify the model predictive uncertainty important for critical applications, e.g., medical image analysis. We propose an unpaired probabilistic image-to-image translation method trained without inter-domain correspondence in an end-to-end manner. The probabilistic nature of this method provides uncertainty estimates for the predictions. Moreover, modelling the residuals between the predictions and the ground-truth with heavy-tailed distributions makes our model robust to outliers and various unseen data.
Notations
Let there be two image domains and . Let the set of images from domain and be defined by (i) , where and (ii) , where , respectively. The elements and represent the image from domain and respectively, and are drawn from an underlying unknown probability distribution and respectively.
Let each image have pixels, and represent the pixel of a particular image . We are interested in learning a mapping from domain to () and to () in an unpaired manner so that the correspondence between the samples from and is not required at the learning stage. In other words, we want to learn the underlying joint distribution from the given marginal distributions and . This work utilizes CycleGANs that leverage the cycle consistency to learn mappings from both directions ( and ).

Cycle Consistency and its interpretation as Maximum Likelihood Estimation (MLE)
CycleGAN enforces an additional structure on the joint distribution using a set of primary networks (forming a GAN) and a set of auxiliary networks. The primary networks are represented by , where represents a generator and represents a discriminator. The auxiliary networks are represented by . While the primary networks learn the mapping , the auxiliary networks learn . Let the output of the generator translating samples from domain (say ) to domain be called . Similarly, for the generator translating samples from domain (say ) to domain be called , i.e., . To simplify the notation, we will omit writing parameters of the networks in the equation. The cycle consistency constraint re-translates the above predictions () to get back the reconstruction in the original domain (,), where, and attempts to make reconstructed images () similar to original input () by penalizing the residuals with norm between the reconstructions and the original input images, giving the cycle consistency,
The underlying assumption when penalizing with the norm is that the residual at \textit{every pixel} between the reconstruction and the input follow \textit{zero-mean and fixed-variance Laplace} distribution, i.e., and with,
where represents the fixed-variance of the distribution, represents the pixel in image , and represents the noise in the pixel for the estimated image . This assumption on the residuals between the reconstruction and the input enforces the likelihood (i.e., , where and ) to follow a factored Laplace distribution:
where minimizing the negative-log-likelihood yields with the following limitations. The residuals in the presence of outliers may not follow the Laplace distribution but instead a heavy-tailed distribution, whereas the i.i.d assumption leads to fixed variance distributions for the residuals that do not allow modelling of heteroscedasticity to aid in uncertainty estimation.
Building Uncertainty-aware Cycle Consistency
We propose to alleviate the mentioned issues by modelling the underlying per-pixel residual distribution as independent but non-identically distributed zero-mean generalized Gaussian distribution} (GGD), i.e., with no fixed shape () and scale () parameters. Instead, all the shape and scale parameters of the distributions are predicted from the networks and formulated as follows:
For each , the parameters of the distribution may not be the same as parameters for other s; therefore, they are non-identically distributed allowing modelling with heavier tail distributions. The likelihood for our proposed model is,
where () represents the pixel of domain 's shape parameter (similarly for others). is the pixel-likelihood at pixel of image (that can represent images of both domain and ) formulated as,
The negative-log-likelihood is given by,
minimizing the negative-log-likelihood yields a new cycle consistency loss, which we call as the uncertainty-aware generalized adaptive cycle consistency loss , given and ,
where is the new objective function corresponding to domain ,
where are the reconstructions for and are scale and shape parameters for the reconstruction , respectively. The norm-based cycle consistency is a special case of with . To utilize , one must have the maps and the maps for the reconstructions of the inputs. To obtain the reconstructed image, (scale map), and (shape map), we modify the head of the generators (the last few convolutional layers) and split them into three heads, connected to a common backbone.
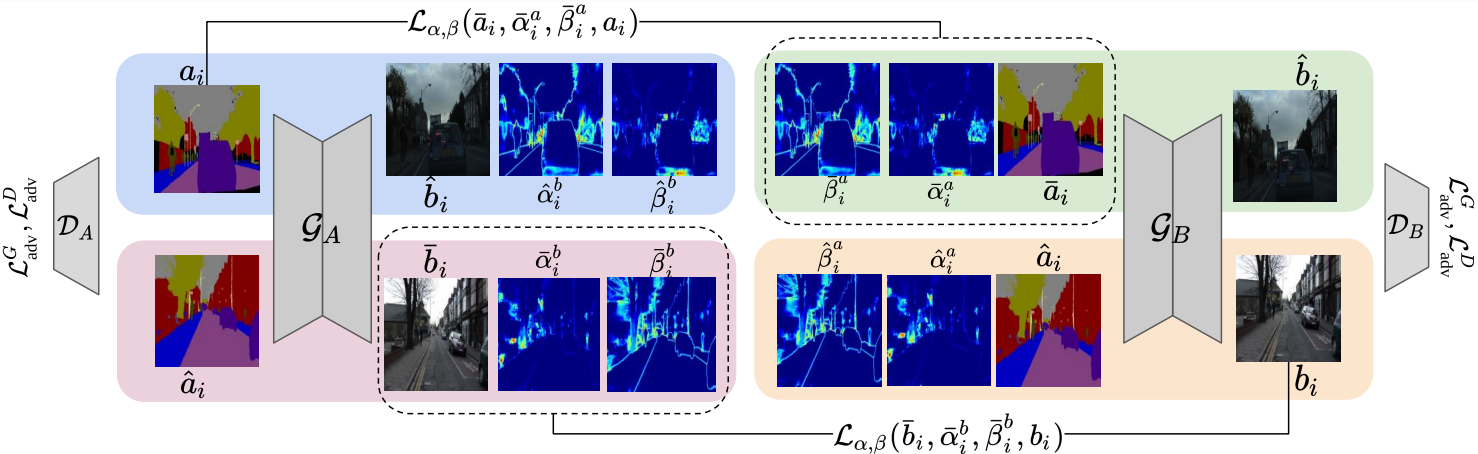
Once we train the model, for every input image, the model will provide the scale () and the shape () maps that can be used to obtain the aleatoric uncertainty given by,
To see the resulting uncertainty maps along with our perturbation analysis of the trained model please check Section 4 of the paper.