
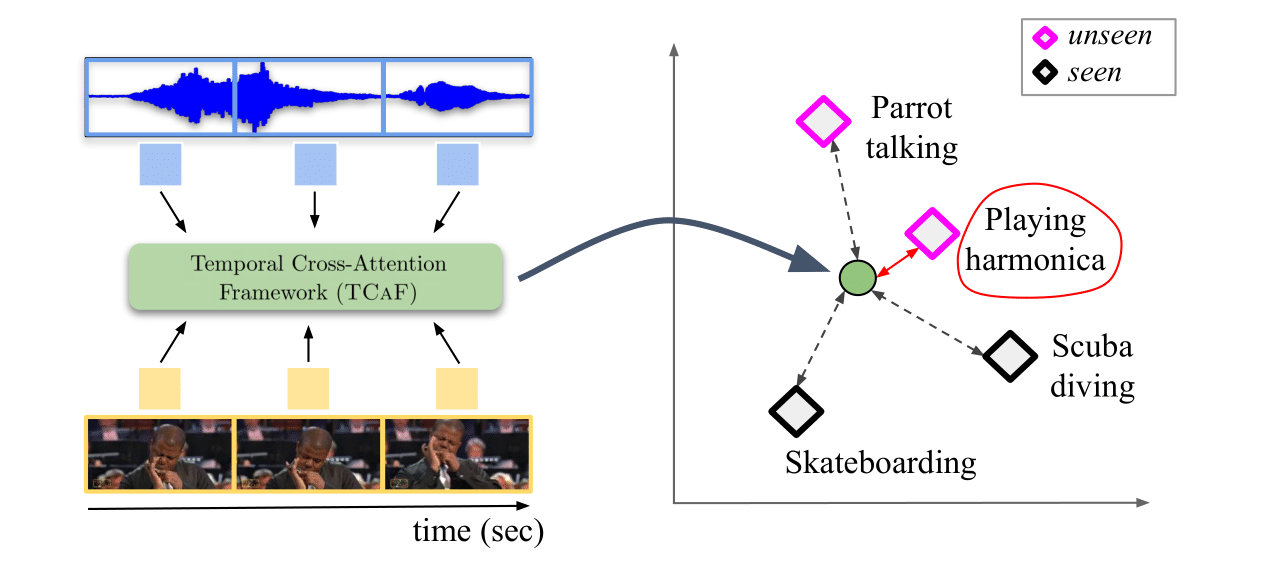
Audio-visual generalised zero-shot learning for video classification requires understanding the relations between the audio and visual information in order to be able to recognise samples from novel, previously unseen classes at test time. The natural semantic and temporal alignment between audio and visual data in video data can be exploited to learn powerful representations that generalise to unseen classes at test time. We propose a multi-modal and Temporal Cross-attention Framework, TCAF, for audio-visual generalised zero-shot learning. Its inputs are temporally aligned audio and visual features that are obtained from pre-trained networks. Encouraging the framework to focus on cross-modal correspondence across time instead of self-attention within the modalities boosts the performance significantly. We show that our proposed framework that ingests temporal features yields state-of-the-art performance on the UCF-GZSLcls, VGGSound-GZSLcls, and ActivityNet-GZSLcls benchmarks for (generalised) zero-shot learning.
Introduction
Learning task-specific audio-visual representations commonly requires a great number of annotated data samples. However, annotated datasets are limited in size and in the labelled classes that they contain. If a model which was trained with supervision on such a dataset is applied in the real world, it encounters classes that it has never seen. To recognise those novel classes, it would not be feasible to train a new model from scratch. Therefore, it is essential to analyse the behaviour of a trained model in new settings. Ideally, a model should be able to transfer knowledge obtained from classes seen during training to previously unseen categories. This ability is probed in the zero-shot learning (ZSL) task. In addition to zero-shot capabilities, a model should retain the class-specific information from seen training classes. This is challenging and is investigated in the so-called generalised ZSL (GZSL) setting which considers the performance on both, seen and unseen classes.
The natural alignment between audio and visual information in videos, e.g. a frog being visible in a frame while the sound of a frog croaking is audible, provides a rich training signal for learning video representations. This can be attributed to the semantic and temporal correlation between the audio and visual information when comparing the two modalities. We encourage our Temporal Cross-attention Framework(TCAF) to put special emphasis on the correlation across the two modalities by employing repeated cross-attention. This attention mechanism only allows attention to tokens from the other modality. This effectively acts as a bottleneck which results in cheaper computations and gives a boost in performance over using full self-attention across all tokens from both modalities.
Finally, past works used temporally averaged features as inputs that were extracted from networks pre-trained on video data. The averaging disregarded the temporal dynamics in videos. We propose to exploit temporal information by using temporal audio and visual data as inputs. This gives a significant boost in performance for the audio-visual (G)ZSL task compared to using temporally averaged input features.
To summarize our contributions:
- We propose a temporal cross-attention framework TCAF for audio-visual (G)ZSL
- Our proposed model achieves state-of-the-art results on UCF-GZSLcls, VGGSound-GZSLcls and ActivityNet-GZSLcls
- We perform a detailed analysis of the use of enhanced cross-attention across modalities and time, demonstrating the benefits of our proposed model architecture and training setup
Model and losses
The goal of our model is to be able to fuse temporal information from both modalities. For this, we use a cross-attention block based on the Transformer architecture, but we put a lot of emphasis on the cross-modal attention between modalities, while supressing the self-attention within each modality. Finally, our model contains just a single output head, which is different than the previous works and which simplifies our model.
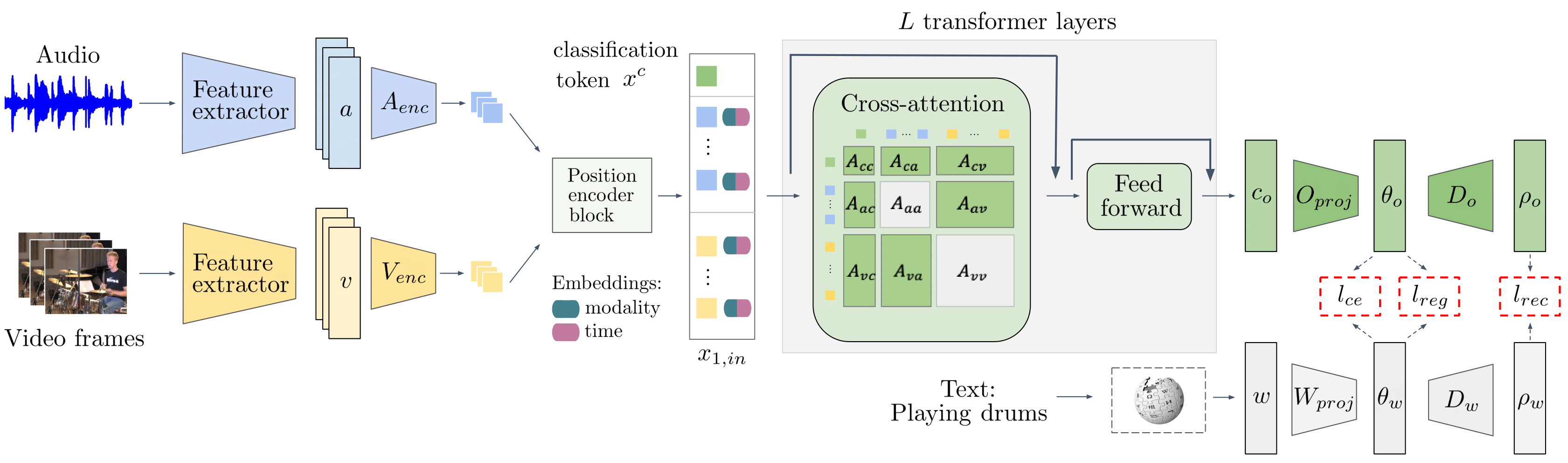
Given the above architecture, at test time, class predictions are obtained by determining the class that corresponds to the textual class label embedding that is closest to the multi-modal represenation .
We also use different types of losses such as:
- Cross-entropy loss updates the probabilities for both the correct and incorrect classes.
- Regression loss directly focuses on reducing the distance between the output embedding for a sample and the corresponding projected word2vec embedding
- Reconstruction loss, which makes sure that the projection of the output embedding and the projection of the class embedding contain a significant amount of information about the semantics of the correct class.
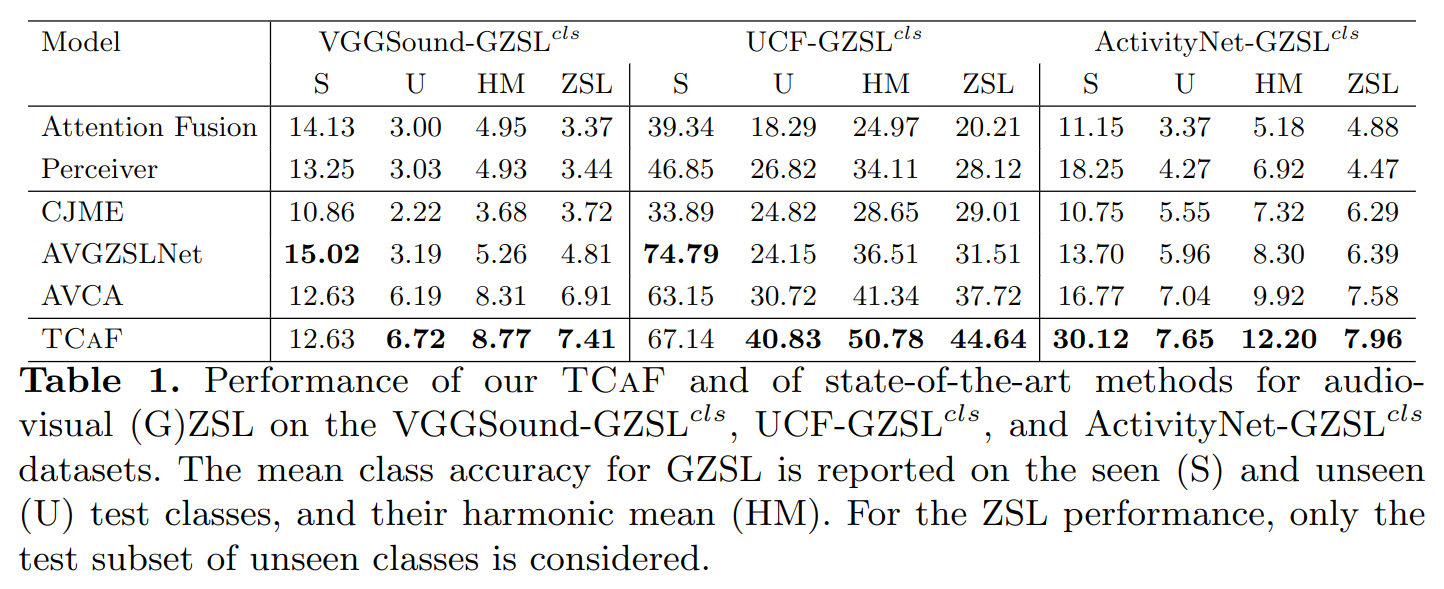
Quantitative results
It can be observed that TCAF obtains state-of-the-art results on all three datasets. TCAF is able to significantly improve the performance over AVCA, which was the previous state-of-the-art. Interestingly, the GZSL performance for TCAF is improved by a more significant margin that the ZSL performance compared to AVCA across all three datasets. This shows that using temporal information and allowing our model to attend across time and modalities is especially beneficial for the GZSL task.
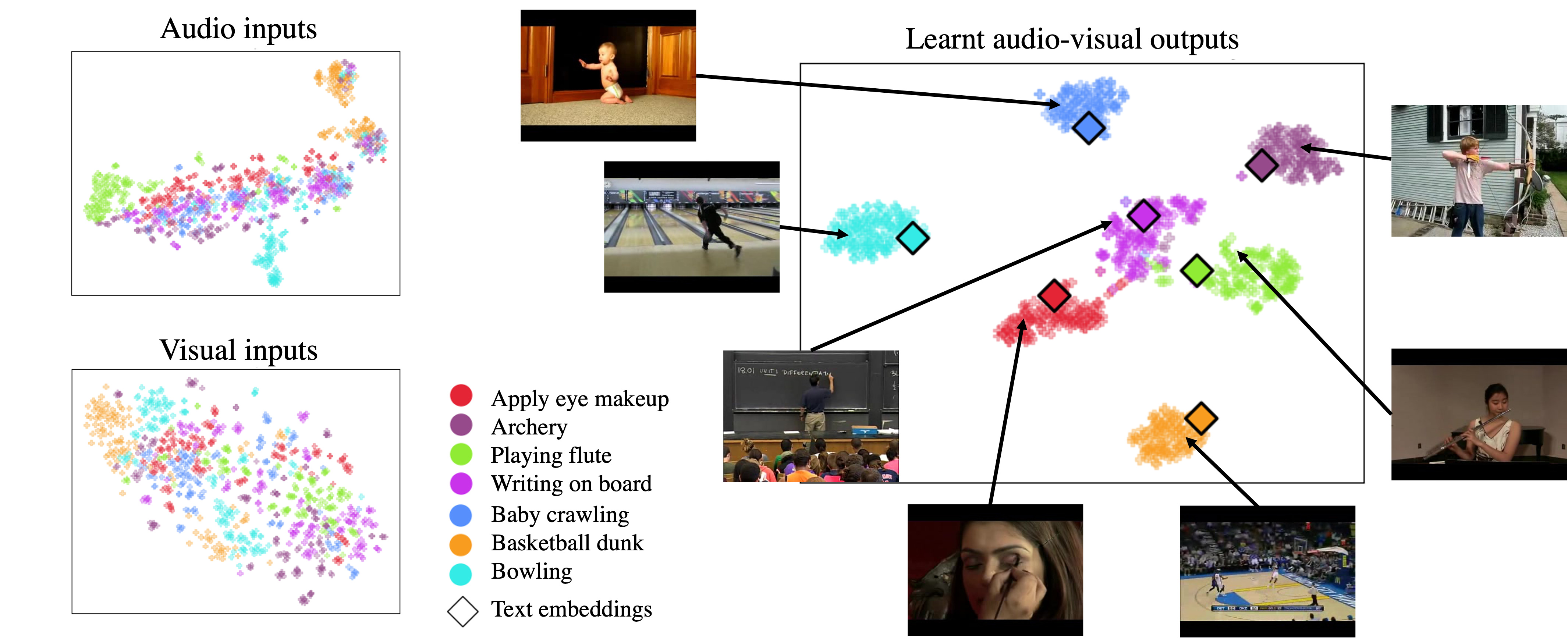
Qualitative results
We present a qualitative analysis of the learnt audio-visual embeddings. For this, we show t-SNE visualisations for the audio and visual input features and for the learnt multi-modal embeddings from 7 classes in the UCF-GZSLcls. We observe that the audio and visual input features are poorly clustered. In contrast, the audio-visual embeddings are clearly clustered for both seen and unseen classes. This suggests that our network is actually learning useful representations for the unseen classes too. Furthermore, the word2vec class label embeddings lie inside the corresponding audio-visual clusters. This confirms that the learnt audio-visual embeddings are mapped to locations that are close to the corresponding word2vec embeddings, showing that our embeddings capture semantic information from the word2vec representations.
For more results and analysis, please refer to the paper.