
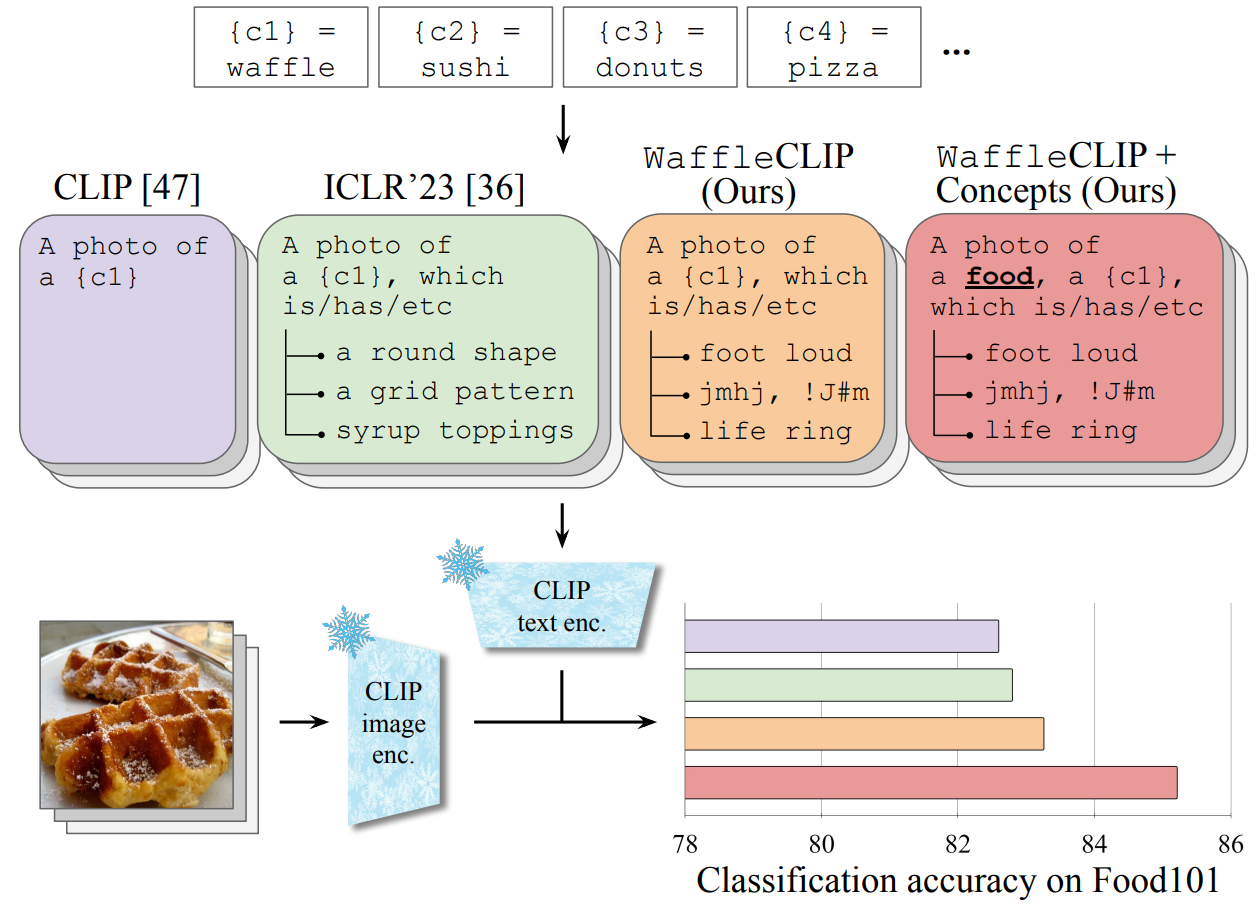
Recent works have shown how visual classification performance of vision-language models such as CLIP can benefit from additional semantic knowledge by utilizing large language models (LLMs) such as GPT-3 to further extend classnames with LLM-generated class descriptors, e.g. “waffle, which has a round shape”, and e.g. averaging retrieval scores over multiple such descriptors. In this work, we study this behaviour in detail and propose WaffleCLIP, a framework for zero-shot visual classification which achieves similar performance gains on a large number of visual classification tasks by simply replacing LLM-generated descriptors with random character and word descriptors without querying external models. We extend these results with an extensive experimental study on the impact and shortcomings of additional semantics introduced via LLM-generated descriptors, and showcase how semantic context is better leveraged by automatically querying LLMs for high-level concepts, while jointly resolving potential class name ambiguities.
Introduction
Task-specific natural language prompts improve the performance of large vision-language models (VLMs). However, if the model does not have access to additional training data, i.e.\ in the zero-shot setting, prompt tuning is not an option. Instead, a promising alternative is querying large language models (LLMs such as GPT-3) to provide additional semantic context and enrich class representations with minimal human intervention, as done in e.g. DCLIP. Experiments show that class-based descriptors on top of classnames, e.g. a round shape for waffle, can provide notable improvements.
However, a closer inspection of LLM-generated descriptors show how multiple descriptors can get assigned to a class despite them likely not co-occurring (e.g."steamed" and "fried"), can contain non-visual attributes (e.g. "a sour and spicy smell"), or can be associated with an ambiguous class interpretation (e.g. "webbed feet" for "Peking duck" as a food item). Hence, the underlying drivers of performance improvements when using generated fine-grained class descriptors are unclear.